학습관리플랫폼 에서 중요한 부분인 프로젝트 평가의 흐름에 대해 설명해보면
학생들이 프로젝트 과제를 수행하고 나서 github URL로 프로젝트 결과물을 제출 →
해당 과정에 속해있는 코치들에게 해당 과제제출건이 랜덤으로 배정 →
코치들이 프로젝트 결과물을 확인하기위해 직접 github URL 에 접속 →
github 상의 쥬피터 노트북 내용을 확인 →
프로젝트 마다 정해져 있는 평가항목을 확인하여 점수와 피드백을 남김.
일련의 과정에서 GPT를 활용해 생산성을 높일수있지않을까 고민하였고
프로젝트 github URL에 접속했을때 확인가능한 code data & 과정별 평가기준 을
프롬프트에 입력하면 평가기준별 점수를 매기고 또 제출한 프로젝트에 대해 코멘트를 생성할 수 있지 않을까?
생각해보게 되었습니다.
간단히 poc 를 진행해보았을떄 생각보다 성능이 나쁘지 않았고 그렇게 GPT를 이용한 자동채점! 기능 개발을 시작하게 되었습니다. 이제부터 어떠한 과정을 거쳐 해당 기능을 개발하였으며 또 진행중 생긴 이슈들을 어떻게 해결했는지에 대해 설명해보겠습니다.
먼저 기존 학습데이터를 분석하였을때 프로젝트는 유형에 따라
A(raw 코드), B(기타 블로그 URL), C(github URL) 으로 나뉘었고
각 유형의 비중이 13%, 0.2%, 86% 로 구성되어있음을 확인하였습니다.
어느정도 포맷이 정해져있는 유형에서 자동채점이 가능하다고 판단되었고, 프로젝트 유형이 A와 C인 경우에 자동채점을 진행하는 것으로 정리했습니다.
A 유형의 경우 아래와 같은 json 형태의 데이터 입니다.
[
{
"code": "import tensorflow as tf\r\nimport numpy as np\r\n\r\nprint(tf.__version__)\r\nprint(np.__version__)",
"submit_block_id": "f28f7c7d-f6a7-4f5c-9174-06d442be1455"
},
{
"code": "import tensorflow as tf\r\nfrom tensorflow import keras\r\n\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\nimport tensorflow_datasets as tfds",
"submit_block_id": "0d9ff2c5-0c80-4ae2-8cae-6d99f4789797"
},
{
"code": "(ds_train, ds_test), ds_info = tfds.load(\r\n 'stanford_dogs',\r\n split=['train', 'test'],\r\n as_supervised=True,\r\n shuffle_files=True,\r\n with_info=True,\r\n)",
"submit_block_id": "0b2020d7-b79b-44fe-921c-0865726c34c1"
},
{
"code": "def normalize_and_resize_img(image, label):\r\n # Normalizes images: `uint8` -> `float32`\r\n image = tf.image.resize(image, [224, 224])\r\n return tf.cast(image, tf.float32) / 255., label\r\n\r\n# basic augmentation\r\ndef augment(image, label):\r\n image = tf.image.random_flip_left_right(image)\r\n image = tf.image.random_brightness(image, max_delta=0.2)\r\n image = tf.clip_by_value(image, 0, 1)\r\n return image, label\r\n\r\ndef onehot(image, label):\r\n label = tf.one_hot(label, num_classes)\r\n return image, label\r\n\r\ndef apply_normalize_on_dataset(ds, is_test=False, batch_size=16, with_aug=False, aug_method=None):\r\n ds = ds.map(\r\n normalize_and_resize_img, \r\n num_parallel_calls=2\r\n )\r\n if not is_test and with_aug:\r\n ds = ds.map(\r\n augment\r\n )\r\n ds = ds.batch(batch_size)\r\n # cutmix augmentation\r\n if not is_test and aug_method=='cutmix':\r\n ds = ds.map(\r\n cutmix,\r\n num_parallel_calls=2\r\n )\r\n # mixup augmentation\r\n elif not is_test and aug_method=='mixup':\r\n ds = ds.map(\r\n mixup,\r\n num_parallel_calls=2\r\n )\r\n else:\r\n ds = ds.map(\r\n onehot,\r\n num_parallel_calls=2\r\n )\r\n if not is_test:\r\n ds = ds.repeat()\r\n ds = ds.shuffle(200)\r\n ds = ds.prefetch(tf.data.experimental.AUTOTUNE)\r\n return ds\r\n\r\nprint('=3')", "submit_block_id": "af271bfa-23ef-4ff6-813f-07942b4e10f4"}, {"code": "def get_clip_box(image_a, image_b):\r\n # image.shape = (height, width, channel)\r\n image_size_x = image_a.shape[1]\r\n image_size_y = image_a.shape[0]\r\n \r\n # get center of box\r\n x = tf.cast(tf.random.uniform([], 0, image_size_x), tf.int32)\r\n y = tf.cast(tf.random.uniform([], 0, image_size_y), tf.int32)\r\n\r\n # get width, height of box\r\n width = tf.cast(image_size_x*tf.math.sqrt(1-tf.random.uniform([], 0, 1)), tf.int32)\r\n height = tf.cast(image_size_y*tf.math.sqrt(1-tf.random.uniform([], 0, 1)), tf.int32)\r\n \r\n # clip box in image and get minmax bbox\r\n x_min = tf.math.maximum(0, x-width//2)\r\n y_min = tf.math.maximum(0, y-height//2)\r\n x_max = tf.math.minimum(image_size_x, x+width//2)\r\n y_max = tf.math.minimum(image_size_y, y+width//2)\r\n \r\n return x_min, y_min, x_max, y_max", "submit_block_id": "2aa0bfd5-9dff-45c2-a8c4-8d46acb6c5ef"}, {"code": "# mix two images\r\ndef mix_2_images(image_a, image_b, x_min, y_min, x_max, y_max):\r\n image_size_x = image_a.shape[1]\r\n image_size_y = image_a.shape[0] \r\n middle_left = image_a[y_min:y_max, 0:x_min, :] # image_b\uc758 \uc67c\ucabd \ubc14\uae65 \uc601\uc5ed\r\n middle_center = image_b[y_min:y_max, x_min:x_max, :] # image_b\uc758 \uc548\ucabd \uc601\uc5ed\r\n middle_right = image_a[y_min:y_max, x_max:image_size_x, :] # image_b\uc758 \uc624\ub978\ucabd \ubc14\uae65 \uc601\uc5ed\r\n middle = tf.concat([middle_left,middle_center,middle_right], axis=1)\r\n top = image_a[0:y_min, :, :]\r\n bottom = image_a[y_max:image_size_y, :, :]\r\n mixed_img = tf.concat([top, middle, bottom],axis=0)\r\n \r\n return mixed_img", "submit_block_id": "b3356272-2e8f-4a73-a8fc-9c5ff60694b2"}, {"code": "# mix two labels\r\ndef mix_2_labels(image_a, image_b, label_a, label_b, x_min, y_min, x_max, y_max, num_classes=120):\r\n image_size_x = image_a.shape[1]\r\n image_size_y = image_a.shape[0] \r\n mixed_area = (x_max-x_min)*(y_max-y_min)\r\n total_area = image_size_x*image_size_y\r\n ratio = tf.cast(mixed_area/total_area, tf.float32)\r\n\r\n if len(label_a.shape)==0:\r\n label_a = tf.one_hot(label_a, num_classes)\r\n if len(label_b.shape)==0:\r\n label_b = tf.one_hot(label_b, num_classes)\r\n mixed_label = (1-ratio)*label_a + ratio*label_b\r\n\r\n return mixed_label", "submit_block_id": "9a8e3592-c60f-481b-b997-f64c4f6604ff"}, {"code": "def cutmix(image, label, prob=1.0, batch_size=16, img_size=224, num_classes=120):\r\n mixed_imgs = []\r\n mixed_labels = []\r\n\r\n for i in range(batch_size):\r\n image_a = image[i]\r\n label_a = label[i]\r\n j = tf.cast(tf.random.uniform([],0, batch_size),tf.int32)\r\n image_b = image[j]\r\n label_b = label[j]\r\n x_min, y_min, x_max, y_max = get_clip_box(image_a, image_b)\r\n mixed_imgs.append(mix_2_images(image_a, image_b, x_min, y_min, x_max, y_max))\r\n mixed_labels.append(mix_2_labels(image_a, image_b, label_a, label_b, x_min, y_min, x_max, y_max))\r\n\r\n mixed_imgs = tf.reshape(tf.stack(mixed_imgs), (batch_size, img_size, img_size, 3))\r\n mixed_labels = tf.reshape(tf.stack(mixed_labels), (batch_size, num_classes))\r\n\r\n return mixed_imgs, mixed_labels", "submit_block_id": "63323261-6aaf-4e51-b92d-173a245a0da0"}, {"code": "# function for mixup\r\ndef mixup_2_images(image_a, image_b, label_a, label_b):\r\n ratio = tf.random.uniform([], 0, 1)\r\n \r\n if len(label_a.shape)==0:\r\n label_a = tf.one_hot(label_a, num_classes)\r\n if len(label_b.shape)==0:\r\n label_b = tf.one_hot(label_b, num_classes)\r\n mixed_image= (1-ratio)*image_a + ratio*image_b\r\n mixed_label = (1-ratio)*label_a + ratio*label_b\r\n \r\n return mixed_image, mixed_label", "submit_block_id": "ae1b48eb-a750-4ac4-ac17-b011d9b5a5eb"}, {"code": "def mixup(image, label, prob=1.0, batch_size=16, img_size=224, num_classes=120):\r\n mixed_imgs = []\r\n mixed_labels = []\r\n\r\n for i in range(batch_size):\r\n image_a = image[i]\r\n label_a = label[i]\r\n j = tf.cast(tf.random.uniform([],0,batch_size), tf.int32)\r\n image_b = image[j]\r\n label_b = label[j]\r\n mixed_img, mixed_label = mixup_2_images(image_a, image_b, label_a, label_b)\r\n mixed_imgs.append(mixed_img)\r\n mixed_labels.append(mixed_label)\r\n\r\n mixed_imgs = tf.reshape(tf.stack(mixed_imgs), (batch_size, img_size, img_size, 3))\r\n mixed_labels = tf.reshape(tf.stack(mixed_labels), (batch_size, num_classes))\r\n\r\n return mixed_imgs, mixed_labels", "submit_block_id": "28c60d1c-c39c-40e8-93ac-b22e6139be64"}, {"code": "num_classes = ds_info.features[\"label\"].num_classes\r\n\r\nds_train_no_aug = apply_normalize_on_dataset(ds_train)\r\nds_train_aug = apply_normalize_on_dataset(ds_train, with_aug=True)\r\n\r\nds_train_cutmix = apply_normalize_on_dataset(ds_train, with_aug=True, aug_method='cutmix')\r\nds_train_mixup = apply_normalize_on_dataset(ds_train, with_aug=True, aug_method='mixup')\r\n\r\nds_test = apply_normalize_on_dataset(ds_test, is_test=True)", "submit_block_id": "518c373f-1f3b-49ec-85a0-584b670fee14"}, {"code": "#num_classes = ds_info.features[\"label\"].num_classes\r\nresnet50 = keras.models.Sequential([\r\n keras.applications.resnet.ResNet50(\r\n include_top=False,\r\n weights='imagenet',\r\n input_shape=(224,224,3),\r\n pooling='avg',\r\n ),\r\n keras.layers.Dense(num_classes, activation='softmax')\r\n])", "submit_block_id": "305f8801-dd57-4b38-b989-ec0ee5953582"}, {"code": "aug_resnet50 = keras.models.Sequential([\r\n keras.applications.resnet.ResNet50(\r\n include_top=False,\r\n weights='imagenet',\r\n input_shape=(224, 224,3),\r\n pooling='avg',\r\n ),\r\n keras.layers.Dense(num_classes, activation = 'softmax')\r\n])", "submit_block_id": "f67a154e-6501-4e8b-a26c-c4e78f25c7d1"}, {"code": "cutmix_resnet50 = keras.models.Sequential([\r\n keras.applications.resnet.ResNet50(\r\n include_top=False,\r\n weights='imagenet',\r\n input_shape=(224,224,3),\r\n pooling='avg',\r\n ),\r\n keras.layers.Dense(num_classes, activation='softmax')\r\n])", "submit_block_id": "8f241cc2-8767-4d6a-b4a9-06e9f652a2a6"}, {"code": "mixup_resnet50 = keras.models.Sequential([\r\n keras.applications.resnet.ResNet50(\r\n include_top=False,\r\n weights='imagenet',\r\n input_shape=(224,224,3),\r\n pooling='avg',\r\n ),\r\n keras.layers.Dense(num_classes, activation='softmax')\r\n])", "submit_block_id": "b247e983-cd02-45dd-9fa5-46e368a879d4"}, {"code": "# LMS \ud658\uacbd\uc744 \uae30\uc900\uc73c\ub85c, \ubaa8\ub378 \ud559\uc2b5\uc5d0 epoch\ub2f9 2~3\ubd84\uc758 \uc2dc\uac04\uc774 \uc18c\uc694\ub429\ub2c8\ub2e4.\r\n# \ud559\uc2b5\uc774 \ub108\ubb34 \uc624\ub798 \uac78\ub9b4 \uacbd\uc6b0 epoch \uc218\ub97c \uc870\uc808\ud574 \uc8fc\uc138\uc694\r\n\r\nEPOCH = 5", "submit_block_id": "50a52852-db35-4f22-b463-b67a8b0488d7"}, {"code": "# no augmentation\r\nresnet50.compile(\r\n loss='categorical_crossentropy',\r\n optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),\r\n metrics=['accuracy'],\r\n)\r\n\r\nhistory_no_aug = resnet50.fit(\r\n ds_train_no_aug, # augmentation \uc801\uc6a9\ud558\uc9c0 \uc54a\uc740 \ub370\uc774\ud130\uc14b \uc0ac\uc6a9\r\n steps_per_epoch=int(ds_info.splits['train'].num_examples/16),\r\n validation_steps=int(ds_info.splits['test'].num_examples/16),\r\n epochs=EPOCH,\r\n validation_data=ds_test,\r\n verbose=1,\r\n use_multiprocessing=True,\r\n)", "submit_block_id": "fdc15c0b-e0f1-4c70-9031-829a6b335aba"}, {"code": "# basic augmentation\r\naug_resnet50.compile(\r\n loss='categorical_crossentropy',\r\n optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),\r\n metrics=['accuracy'],\r\n)\r\n\r\nhistory_aug = aug_resnet50.fit(\r\n ds_train_aug, # augmentation \uc801\uc6a9\ud55c \ub370\uc774\ud130\uc14b \uc0ac\uc6a9\r\n steps_per_epoch=int(ds_info.splits['train'].num_examples/16),\r\n validation_steps=int(ds_info.splits['test'].num_examples/16),\r\n epochs=EPOCH,\r\n validation_data=ds_test,\r\n verbose=1,\r\n use_multiprocessing=True,\r\n)", "submit_block_id": "8c7c6714-fd9d-4e65-971e-4e1a983c1f85"}, {"code": "# basic augmentation + cutmix\r\ncutmix_resnet50.compile(\r\n loss='categorical_crossentropy',\r\n optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),\r\n metrics=['accuracy'],\r\n)\r\n\r\nhistory_cutmix = cutmix_resnet50.fit(\r\n ds_train_cutmix, # cutmix \uc801\uc6a9\ud55c \ub370\uc774\ud130\uc14b \uc0ac\uc6a9\r\n steps_per_epoch=int(ds_info.splits['train'].num_examples/16),\r\n validation_steps=int(ds_info.splits['test'].num_examples/16),\r\n epochs=EPOCH,\r\n validation_data=ds_test,\r\n verbose=1,\r\n use_multiprocessing=True,\r\n)", "submit_block_id": "380aec46-b47b-4ec4-8516-b4f7890e5b31"}, {"code": "# basic augmentation + mixup\r\nmixup_resnet50.compile(\r\n loss='categorical_crossentropy',\r\n optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),\r\n metrics=['accuracy'],\r\n)\r\n\r\nhistory_mixup = mixup_resnet50.fit(\r\n ds_train_mixup, # mixup \uc801\uc6a9\ud55c \ub370\uc774\ud130\uc14b \uc0ac\uc6a9\r\n steps_per_epoch=int(ds_info.splits['train'].num_examples/16),\r\n validation_steps=int(ds_info.splits['test'].num_examples/16),\r\n epochs=EPOCH,\r\n validation_data=ds_test,\r\n verbose=1,\r\n use_multiprocessing=True,\r\n)", "submit_block_id": "19e8bf71-d6a4-4fdd-a3c3-502912b6147d"}, {"code": "plt.figure(figsize=(12, 8))\r\nplt.plot(history_no_aug.history['val_accuracy'], 'r')\r\nplt.plot(history_aug.history['val_accuracy'], 'b')\r\nplt.plot(history_cutmix.history['val_accuracy'], 'g')\r\nplt.plot(history_mixup.history['val_accuracy'], 'k')\r\nplt.title('Model validation accuracy')\r\nplt.ylabel('Accuracy')\r\nplt.xlabel('Epoch')\r\nplt.legend(['no augmentation', 'with augmentation', 'with cutmix', 'with mixup'])\r\nplt.show()", "submit_block_id": "17794101-27ef-4fdd-accd-9099c71f59fd"
}
]
C 유형의 경우 아래 예시와 같은 jupyter notebook 형태입니다.
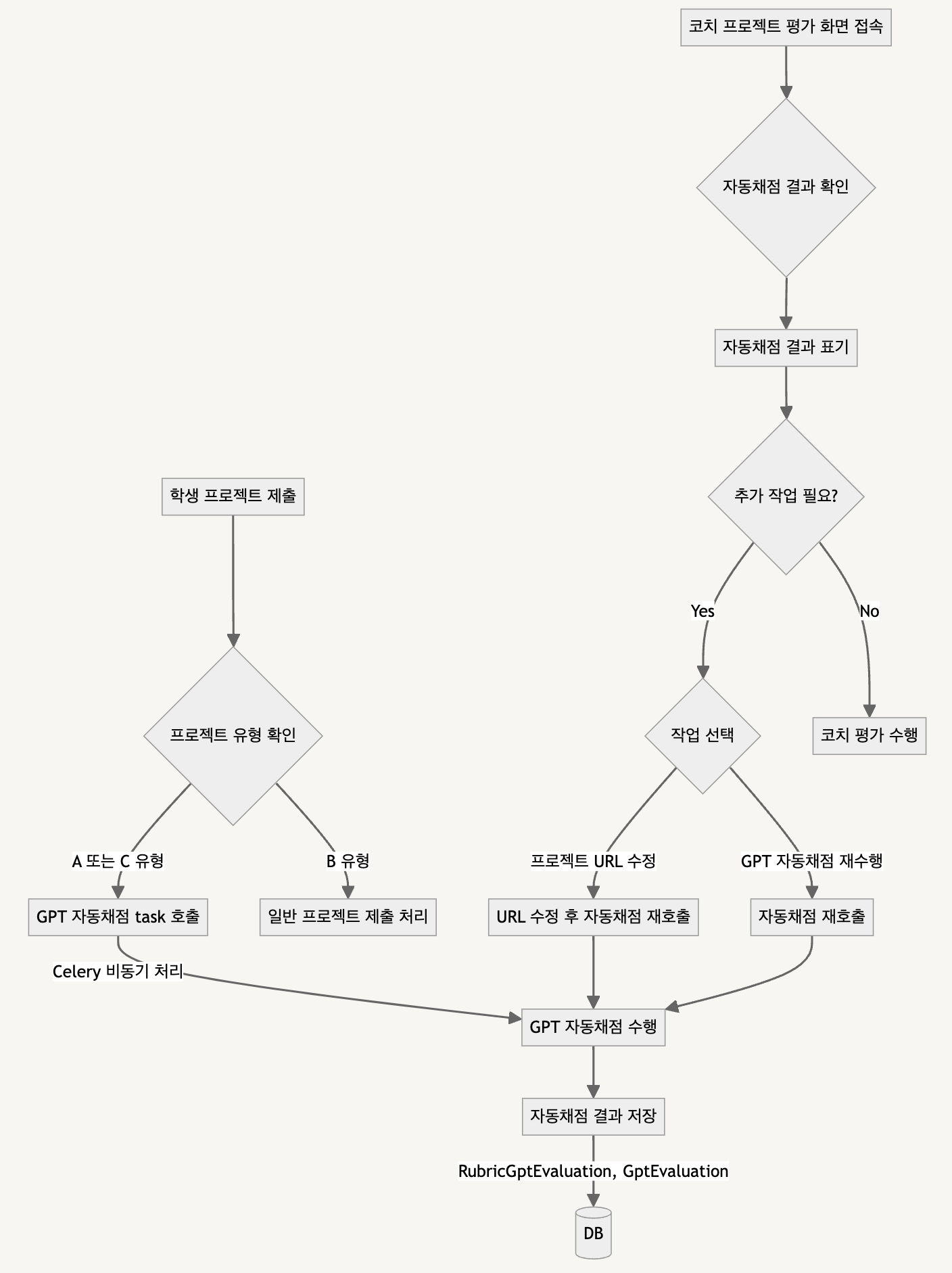
큰 구조는 학생이 프로젝트를 제출할때에 위 프로젝트 유형(A, C)에 해당하는지 체크하여
해당 조건을 만족하면 gpt 자동채점 task를 celery 를 사용하여 비동기로 호출하고
자동채점 결과는 별도 DB(RubricGptEvaluation, GptEvaluation) 에 저장하는 구조입니다.
이후 코치가 프로젝트 평가화면에 접속했을때 자동채점 결과가 있다면 해당 정보를 표기하여
평가를 할때에 해당 정보를 참고하여 평가를 할수 있게 하였습니다.
또한 해당 화면에는 잘못 제출된 프로젝트 URL을 코치가 직접 수정할수 있고 또 갱신된 URL 기준으로 자동채점을 다시 수행가능해야 한다는 요구사항을 반영하여 직접 gpt 자동채점을 호출하여 결과를 확인할 수 있는 버튼을 추가하였습니다.
# task.py
def 프로젝트_제출함수 ():
...
# GPT 자동 채점 실행
if submit_type in ["projA", "projC"]:
get_gpt_evaluation_feedback.delay(node_progrs_id, rubric_id_list, submit_type, submit_data)
...
별도의 task.py 파일을 생성하여 아래와 같이 구성하였습니다.
get_gpt_evaluation_feedback() 함수는
앞서 프로젝트_제출함수() 에서 호출하는 task job 으로
자동채점을 위한 학습정보 id, 평가기준 id, 프로젝트 유형, 프로젝트 data 를 인자로 합니다.
@shared_task
def get_gpt_evaluation_feedback(node_progrs_id, rubric_id_list, submit_type, submission_data):
processed_data = process_submission(submit_type, submission_data) # 1
if not processed_data:
logger.warning(f"No processed data for NodeProgrs ID: {node_progrs_id}")
return
# Perform GPT evaluation
try:
rubric_info = get_rubric_details(rubric_id_list) # 2
response_data = evaluate_with_gpt(node_progrs_id, rubric_info, processed_data) # 3
save_gpt_evaluation(node_progrs_id, rubric_id_list, response_data) # 4
logger.info(f"GPT evaluation feedback recorded for NodeProgrs ID: {node_progrs_id}")
except Exception as e:
logger.error(f"Error processing GPT evaluation feedback: {e}")
위 코드를 순서대로 자세히 살펴보면, #1 process_submission() 메서드에서는
프로젝트 유형에 따라 code와 github URL을 구분하여 github URL인 경우 파일의 확장자가 ipynb 쥬피터 노트북 인지 체크하고 “https://raw.githubusercontent.com/” 로 시작하는 github raw data를 가져올 수 있는 주소로 변환한 이후
parsing 하여 code가 담긴 code cell 부분만 가져오도록 처리하였습니다.
#2 get_rubric_details() 메서드에서는
평가기준 id를 가지고 평가기준에 대한 상세정보를 조회하여 자동채점을 진행 하기 위한 data 를 셋업하였습니다.
#3 evaluate_with_gpt() -call_chat_gpt_api()- 메서드에서는
주어진 자료들을 종합하여 gpt api를 호출, 자동채점 응답을 출력합니다.
call_chat_gpt_api() 메서드를 보면 (아래의 코드를 참고, evaluate_with_gpt() 메서드 내부를 확인하면 call_chat_gpt_api()를 호출하게 되어있고 gpt api 를 호출하는 관련로직은 call_chat_gpt_api() 메서드에 작성되어 있음)
gpt를 이용해 자동채점을 하기 위해선 적절한 프롬프트를 구성해야합니다.
messages = [
{
"role": "system",
"content": (
"당신은 AI 멘토로서 학생의 코드 제출을 평가하고 특정 JSON 형식으로 평가 결과를 출력하는 임무를 맡고 있습니다. "
"각 루브릭에 대해 지정된 범위 내에서 점수를 부여하고 상세한 피드백을 제공해주세요. "
"마지막으로 전체 프로젝트에 대한 종합적인 의견을 한국어로 제공해주세요. "
"각 루브릭 기준에 대한 상세한 피드백과 전체 의견을 단락으로 구성하여 JSON 형식으로 제공해주세요. 결과물은 명확한 단락 구성과 문장 별 개행을 포함하여 가독성을 높여주세요:\n"
"{\n"
" 'rubric_evaluations': [\n"
" {'score': <점수>, 'comment': <코멘트>},\n"
" ... (각 루브릭에 대해)\n"
" ],\n"
" 'overall_comment': <전체 코멘트>\n"
"}"
)
},
{
"role": "system",
"content": "Submitted Code for Evaluation:"
},
{
"role": "system",
"content": processed_data
},
]
아래에서 client.chat.completions.create() 에서 response_format을 json 형태로 따로 지정하긴 했지만 프롬프트 내에서도 출력 포맷을 다시 한번 json으로 명시적으로 지정하고 각 평가기준(루브릭)에 대해서 개별 점수와 의견을 채점하고
또 프로젝트 전체에 대한 의견을 제공할 것을 이야기했습니다.
프롬프트를 구성할때 응답값의 형태를 json으로 보장하기 위해 json mode가 지원되는 모델을 사용하였습니다.
“gpt-4-1106-preview” 모델을 사용하였고 response_format을 “json_object” 로 지정하였습니다.
response = client.chat.completions.create(
model="gpt-4-1106-preview",
response_format={"type": "json_object"},
messages=messages
)
rubric_descriptions = "다음은 이 프로젝트를 평가하기 위한 루브릭 세부 사항입니다:\n\n"
for rubric in rubric_info:
rubric_descriptions += f"메트릭 '{rubric['metric']}'은 0점 또는 1점으로 평가할 수 있습니다. 상세 평가 기준은 다음과 같습니다:\n"
for category in rubric['categories']:
rubric_descriptions += f" - '{category['eval_standard']}'에 대한 점수 {category['score']}\n"
messages.append({
"role": "user",
"content": rubric_descriptions
})
messages.append({
"role": "user",
"content": (
"이제 전체 프로젝트에 대한 종합적인 의견을 JSON 형식으로 제공해주세요. 결과물에 적절한 이모지를 포함시켜 학습자의 이해를 돕고, 글의 의미를 강조해주세요.\n"
"AI/SW 멘토로서 학생의 프로젝트에 대한 균형 잡힌, 명확하고 구체적인 피드백을 한국어로 제공해주세요. 프로젝트의 강점과 개선할 점을 상세히 언급하고, 학습자가 더 발전할 수 있도록 도움이 되는 추가 자료나 참고할 만한 사례도 제시해주세요. \n"
"친절하고 격려하는 어조로 피드백을 구성하여 학습자의 자신감을 증진시키고, 기술적 성장을 위한 명확한 방향을 제시해주세요."
)
})
각 평가기준의 점수범위를 0점 또는 1점이라고 명시하였습니다. 그렇지 않고 1점까지 가능하다고 하였을때는 소수점을 포함한 값을 출력하기도 하여 0점 또는 1점이라고 명시적으로 이야기하였습니다.
프로젝트 전체에 대한 평가의견 부분에서는 학생이 느끼기에 딱딱하지 않고 친근하게 느낄수있게 어조와 담길 내용의 목표를 지정하였습니다.
추가로 summary_data() 를 조회하는 부분이 나오는데 초기 기능 개발시 설계했던 것은
평가 데이터가 어느정도 쌓였을때
점수별 이전 데이터를 가져와 자동채점에 반영하려고 하였습니다.
예를 들면
0점을 받은 평가데이터와 코치의 피드백… X n개
1점을 받은 평가데이터와 코치의 피드백… X n개
2점을 받은 평가데이터와 코치의 피드백… X n개
3점을 받은 평가데이터와 코치의 피드백… X n개
+
현재 학생이 제출한 프로젝트 데이터
+
평가기준
과 같이 프롬프트를 구성하여 gpt의 응답을 좀더 강건하게 하고싶었습니다. 이 내용은 이후 RAG 부분에서 어떻게 진행해 볼 수 있을지 더 이야기해보겠습니다.
아래는 call_chat_gpt_api() 함수의 전체 코드입니다.
def call_chat_gpt_api(node_progrs_id, rubric_info, processed_data):
logger.info(f"Calling Chat GPT API for NodeProgrs ID: {node_progrs_id}")
summary_data = get_summary_evaluation_data(node_progrs_id)
messages = [
{
"role": "system",
"content": (
"당신은 AI 멘토로서 학생의 코드 제출을 평가하고 특정 JSON 형식으로 평가 결과를 출력하는 임무를 맡고 있습니다. "
"각 루브릭에 대해 지정된 범위 내에서 점수를 부여하고 상세한 피드백을 제공해주세요. "
"마지막으로 전체 프로젝트에 대한 종합적인 의견을 한국어로 제공해주세요. "
"각 루브릭 기준에 대한 상세한 피드백과 전체 의견을 단락으로 구성하여 JSON 형식으로 제공해주세요. 결과물은 명확한 단락 구성과 문장 별 개행을 포함하여 가독성을 높여주세요:\n"
"{\n"
" 'rubric_evaluations': [\n"
" {'score': <점수>, 'comment': <코멘트>},\n"
" ... (각 루브릭에 대해)\n"
" ],\n"
" 'overall_comment': <전체 코멘트>\n"
"}"
)
},
{
"role": "system",
"content": "Submitted Code for Evaluation:"
},
{
"role": "system",
"content": processed_data
},
]
if summary_data:
messages.append({
"role": "system",
"content": "Summary of Previous Evaluations:"
})
messages.append({
"role": "system",
"content": summary_data # 요약된 평가 내용
})
rubric_descriptions = "다음은 이 프로젝트를 평가하기 위한 루브릭 세부 사항입니다:\n\n"
for rubric in rubric_info:
rubric_descriptions += f"메트릭 '{rubric['metric']}'은 0점 또는 1점으로 평가할 수 있습니다. 상세 평가 기준은 다음과 같습니다:\n"
for category in rubric['categories']:
rubric_descriptions += f" - '{category['eval_standard']}'에 대한 점수 {category['score']}\n"
messages.append({
"role": "user",
"content": rubric_descriptions
})
messages.append({
"role": "user",
"content": (
"이제 전체 프로젝트에 대한 종합적인 의견을 JSON 형식으로 제공해주세요. 결과물에 적절한 이모지를 포함시켜 학습자의 이해를 돕고, 글의 의미를 강조해주세요.\n"
"AI/SW 멘토로서 학생의 프로젝트에 대한 균형 잡힌, 명확하고 구체적인 피드백을 한국어로 제공해주세요. 프로젝트의 강점과 개선할 점을 상세히 언급하고, 학습자가 더 발전할 수 있도록 도움이 되는 추가 자료나 참고할 만한 사례도 제시해주세요. \n"
"친절하고 격려하는 어조로 피드백을 구성하여 학습자의 자신감을 증진시키고, 기술적 성장을 위한 명확한 방향을 제시해주세요."
)
})
try:
response = client.chat.completions.create(
model="gpt-4-1106-preview",
response_format={"type": "json_object"},
messages=messages
)
logger.info(f"Received response from Chat GPT API for NodeProgrs ID: {node_progrs_id}")
print(response.choices[0].message.content)
return response.choices[0].message.content
except Exception as e:
logger.error(f"Error calling Chat GPT API: {e}")
return None
이어지는 #4 save_gpt_evaluation() 메서드에서는
자동채점된 결과를 별도 생성한 테이블 RubricGptEvaluation, GptEvaluation 에 저장합니다.
RubricGptEvaluation 에는 평가 id별 평가기준 점수와 평가의견을 저장하였고
GptEvaluation 에는 학습정보 id 별 전체 평가의견을 저장하였습니다.
코치가 프로젝트 평가화면에 접속하였을때 자동채점된 결과가 있는 경우에 자동채점 결과를 확인할 수 있게 하였습니다.
또한 자동채점 대상이지만 자동채점시 에러가 발생하여 자동채점 결과가 없는 경우
또는 사용자의 오입력으로 다시 채점해야하는 경우와 같은 예외 경우를 고려하여
자동채점을 직접 진행하기 위해 call_chat_gpt_api()를 호출하는 api를 따로 구현하였습니다.
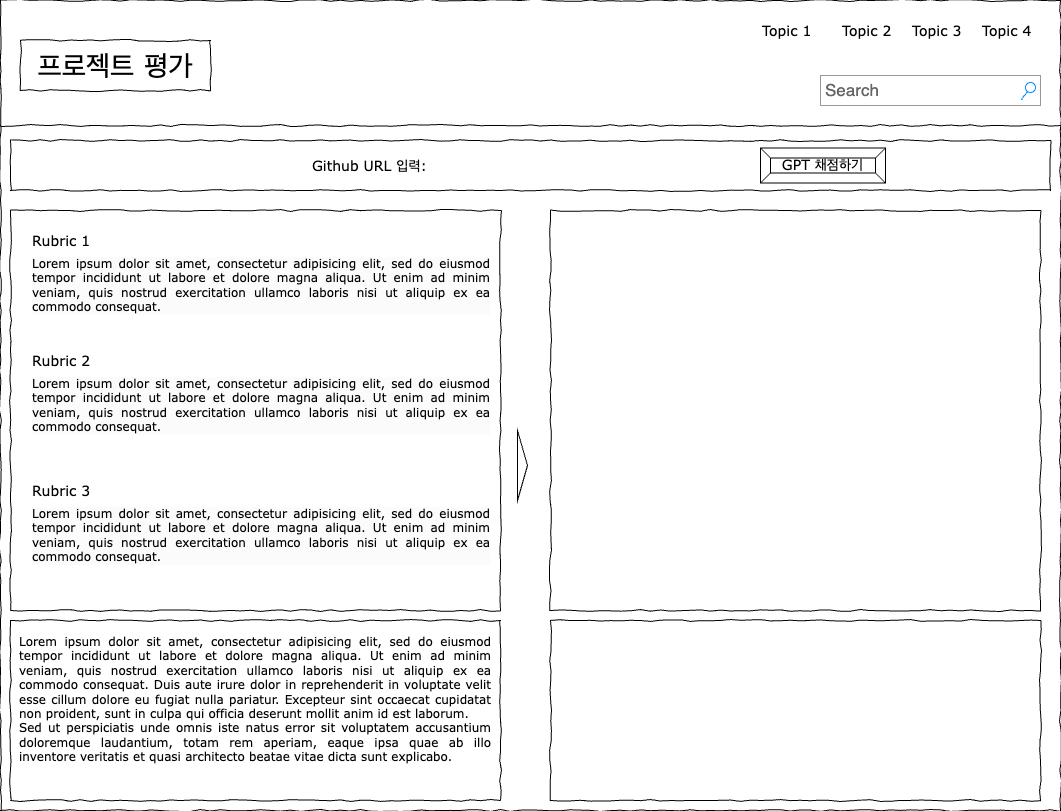
코치가 평가화면에 접속하면 (위 예시화면) 왼쪽에는 평가 기준별 gpt 자동채점 결과,
프로젝트 전체에 대한 평가의견 순서로 확인할수 있으며
해당 데이터들은 실제 평가에 활용될 수 있을뿐 실제 평가결과에 바로 적용되지 않습니다.
자동채점 결과를 확인하고 잘못된 부분이 있다면 수정후 평가를 진행할 필요가 있다고 생각되었기 때문입니다.
코치는 해당 자동채점 결과 데이터를 활용할 수 있고 본인이 직접 학생의 프로젝트 평가의견을 남길수있습니다.
또한 자동채점 결과가 없는 경우 Github URL을 입력하고 우측 상단의 “GPT 채점하기”버튼을 클릭하여 자동채점을 직접 요청할수 있습니다.
샘플링한 gpt 자동채점 결과를 확인해보면 평가기준 별 스코어와 평가의견은 아래와 같습니다.
해당하는 평가점수와 이모티콘이 포함된 평가의견을 확인할수 있습니다.
0 점/ 평가 지표 선택 및 근거 서술: 프로젝트에서는 다양한 머신러닝 모델을 사용하고, 각 모델의 성능을 평가하기 위해 ‘classification_report’를 활용하셨습니다. 그러나 각 모델에 적합한 평가 지표 선택 이유와 근거에 대한 서술이 누락되어 있어, 이 부분은 개선이 필요합니다. 🚧
1 점/ 모델 학습 및 평가: 다양한 머신러닝 모델(Decision Tree, Random Forest, SVC, SGD Classifier, Logistic Regression, XGBClassifier)을 적용하여 학습 및 테스트를 수행하고, 각 모델에 대한 성능 평가를 ‘classification_report’를 통해 정상적으로 출력한 점이 인상적입니다. 모든 모델이 정상 작동하여 결과값을 얻어내셨기 때문에 이 부분에 대해 만점을 부여합니다. ✅
1 점/ 데이터 셋 구성 파악 및 데이터 이해: 학습자께서 제출하신 코드를 살펴보았을 때, ‘digits’ 데이터셋에 대한 feature 및 label의 선정을 위해 기본적인 데이터 분석을 수행하신 것을 확인할 수 있습니다. 특히, **data**.head(), target, target_names, value_counts() 및 **describe**() 메서드를 사용하여 데이터셋의 구성을 파악함으로써 데이터를 충분히 이해하려는 노력이 엿보입니다. 📊
아래는 프로젝트 전체에 대한 gpt 자동채점 평가의견입니다.
안녕하세요! 프로젝트를 열심히 수행해주셔서 감사합니다.
우선, 데이터 분석부터 다양한 머신러닝 모델을 적용하여 실험한 점은 매우 훌륭합니다.
🎉 특히, 하이퍼파라미터 튜닝을 위해 RandomizedSearchCV를 사용한 부분은 학습의 탄탄한 이해를 바탕으로 한 좋은 접근입니다.
👍 하지만, 평가 지표 선택과 그에 대한 근거가 명확하게 서술되지 않았어요.
모델의 성능을 평가할 때 각 지표가 가지는 의미와 중요성을 이해하고, 프로젝트의 목적과 데이터의 특성에 따라 적합한 지표를 선택하는 것은 매우 중요합니다.
예를 들어, 클래스 불균형이 있는 경우 정확도(Accuracy)만으로는 충분한 평가가 되지 않을 수 있으므로, F1 스코어나 AUC-ROC 등의 지표를 함께 고려할 수 있습니다.
또한 모델의 성능을 더욱 향상시키고자 한다면 교차 검증 방법, 앙상블 모델의 사용 등 다양한 시도를 해볼 수 있습니다.
다음 프로젝트에는 각 지표들이 왜 중요한지를 명시하면서, 자신의 선택에 대한 타당한 근거를 추가해보시길 바랍니다.
힘내세요! 💪
자동채점 기능 개발은 무사히 완료되었지만
실제 운영환경에 반영하고 나서 확인한 이슈들이 있었습니다.
- context 길이 초과로 에러 발생
먼저 아주 드물게 발생하긴 했지만 제출한 github url 상의 code 데이터가 길어
gpt api를 호출시 context 길이 초과로 에러가 발생하고 이후에 자동채점이 진행되지 않는 경우가 발생했습니다.
예를 들면 아래와 같은 에러가 발생하였는데,
Error calling Chat GPT API: Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 23305 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
해당 메시지는 프롬프트 길이가 정해진 16385 token을 초과하여 23305 token이라 메시지 길이를 줄여야 한다는 내용입니다.
일반적으로 생각했을때 메시지 길이를 단순히 줄이는 것을 생각할 수 있지만
이렇게 되면 평가에 중요한 정보가 뒤에 있는 경우 전체 자동채점에 영향을 미칠수 있어서 어떻게 줄일지에 대해 고민을 해야했습니다.
또 다른 방법으로는 token의 최대길이를 초과하는 경우 메시지를 분할해서 전송하는 방법,
예를 들어 16385 token을 초과하는 경우 메시지를 16385 token 단위로 분할한 다음
각각의 결과를 확인해 종합하는 방법이 있습니다.
2가지 방법중 좀 더 적합한 것은 분할해서 전송한 후 각각의 결과값을 다시 종합하는 2번 방법이었으나
마지막에 실제 적용한 방법은 다른 모델을 사용 하는 것이었습니다.
json 모드를 사용해야하는 조건이 있었기에 해당 기능을 제공하는 모델중에 선택을 했으며
최초 모델은 “gpt-3.5-turbo-1106” 를 사용하였고
CONTEXT WINDOW가 16,385 tokens이고 training data 시점이 2021년 9월이었습니다.
이후 “gpt-4-1106-preview” 모델의 경우
CONTEXT WINDOW가 128,000 tokens이고 training data 시점도 2023년 4월로 확연한 차이를 보였다.
모델 업데이트 시점 이후에는 해당 에러는 따로 발생하지않았습니다.
- RAG (Retrieval-Augmented Generation)
앞에서도 잠깐 언급하였지만 평가 데이터가 어느정도 쌓였다면 새로운 프로젝트 건에 대해 자동채점시
이미 평가되어 참고할 데이터가 있는지 조회하는 부분이 있었습니다.
이미 쌓여있는 자동채점 데이터를 신규 채점건에 반영하는 것은
평가 일관성을 유지하고 평가 품질의 향상을 기대할수있으며 평가 시간을 단축할 수 있다는 이점이 있습니다.
향후 RAG을 구성하게 된다면 아래와 같은 방법으로 진행해볼 수 있을 것입니다.
-.수집된 과거 자동채점 데이터를 필요한 경우 정제하거나 전처리
-.질의 응답 쌍을 생성. 예를 들어 과제 내용과 코드를 질의로 그에 대한 채점 결과와 피드백을 응답으로
-.질의 응답 쌍을 효과적으로 검색할수 있도록 ElasticSearch, Lucene 과 같은 검색엔진을 활용하여 색인구축
-.새로운 과제가 제출되면 과제의 내용과 코드를 질의로 사용하여 기존 채점 데이터에서 가장 유사한 과제를 검색
-.검색된 유사 과제의 채점결과와 피드백을 현재 과제의 자동채점에 활용
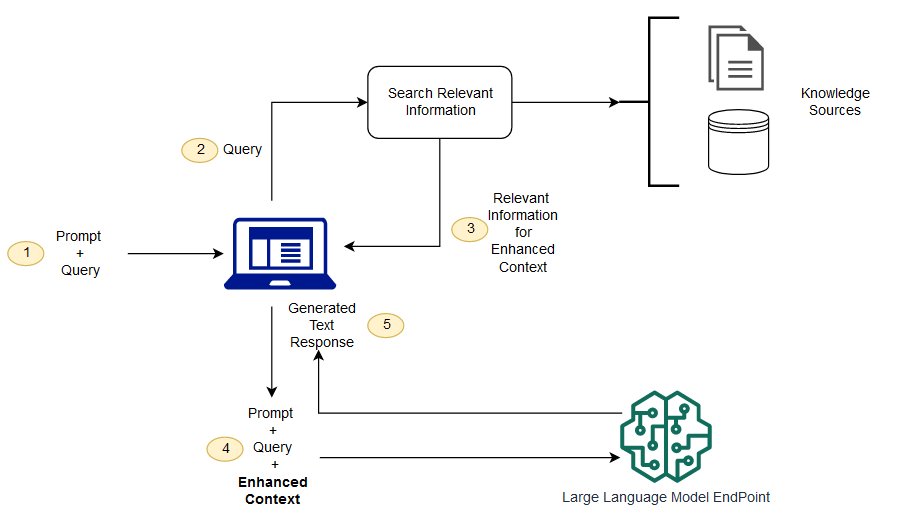 그림 2.LLM과 함께 RAG를 사용하는 개념적 흐름 -출처: https://aws.amazon.com/ko/what-is/retrieval-augmented-generation/
그림 2.LLM과 함께 RAG를 사용하는 개념적 흐름 -출처: https://aws.amazon.com/ko/what-is/retrieval-augmented-generation/
- 자동채점을 사용자가 직접 실행시 결과값을 스트리밍으로 전달할수 있을까?
from rest_framework.response import StreamingHttpResponse
from django.http import HttpResponse
class ProcessGptEvaluationView(APIView):
permission_classes = [CoachOnly]
def post(self, request, node_progrs_id):
submission_id = request.data.get('submission_id')
submit_type = request.data.get('submit_type')
submit_data = request.data.get('submit_data')
# ... (기존 코드 생략) ...
# Perform GPT evaluation
try:
rubric_info = get_rubric_details(rubric_id_list)
# ChatGPT API 호출 시 stream=True 설정
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are an AI assistant."},
{"role": "user", "content": processed_data}
],
stream=True
)
def generate_response():
collected_chunks = []
for chunk in response:
chunk_message = chunk['choices'][0]['delta'].get('content', '')
collected_chunks.append(chunk_message)
yield chunk_message
# 전체 응답 메시지 조합
full_response = ''.join(collected_chunks)
# 데이터베이스에 저장
save_gpt_evaluation(node_progrs_id, rubric_id_list, full_response)
logger.info(f"GPT evaluation feedback recorded for NodeProgrs ID: {node_progrs_id}")
# 스트리밍 응답 반환
return StreamingHttpResponse(generate_response(), content_type='text/plain')
except Exception as e:
logger.error(f"Error in GPT evaluation: {str(e)}")
return HttpResponse(status=500)
위 ProcessGptEvaluationView () 코드는 직접 gpt api를 호출하여 자동채점을 진행하는 기존 코드를
stream 형태로 변환한 코드입니다.
결과값을 stream 화 하기 위해선
먼저 openai.ChatCompletion.create() 에서 stream 파라미터의 값을 True로 지정해야 합니다.
그리고 generate_response() 제너레이터 함수를 정의하여 응답을 chunk 단위로 처리합니다.
collected_chunks 리스트에 chunk 를 별도 저장합니다.
전체 응답이 수신완료되면 기존 응답 메시지를 full_response 로 조합하고 save_gpt_evaluation() 메서드를 사용하여 데이터베이스에 저장합니다.
위 코드의 마지막 부분을 보면 StreamingHttpResponse 를 사용하여 스트리밍 응답을 반환합니다.
return StreamingHttpResponse(generate_response(), content_type=’text/plain’)
StreamingHttpResponse 에는 앞서 선언한 generate_response() 제너레이터를 응답의 콘텐츠로 전달합니다.
위와 같이 코드를 작성하면 gpt 화면에서처럼 응답값을 일정단위로 전달받아 화면에서 확인할수 있습니다.