끝없이 이어지는 슬랙 에러알림과 만난적이 있는가?
그 때의 긴장감과 두려움은 다시는 겪고 싶지않다. 그래서 누군가는 내가 겪은 상황을 조금은 빠르게 대처할 수 있게 글로써 이번에 해결한 장애상황을 정리해본다.
목요일 오후 8시, 모두가 퇴근해서 각자의 시간을 보내고 있을 무렵.
하나씩 그러나 끝없이 올라오는 슬랙 에러 알림.
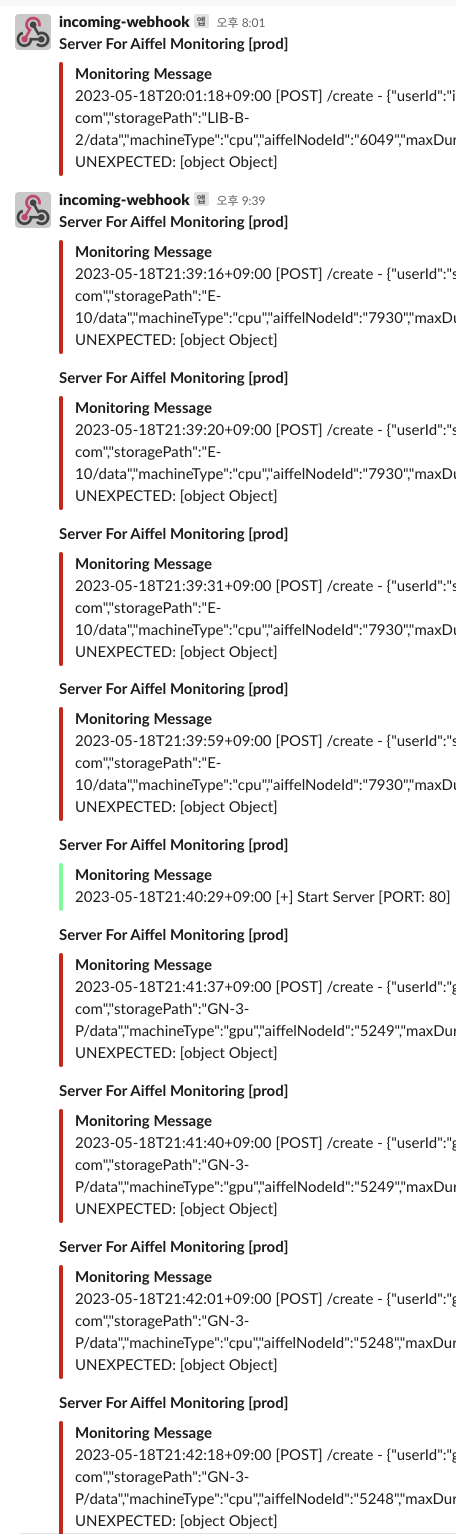
퇴근후 발생한 장애상황을 뒤늦게 받은 전화를 통해 알게되었고,
전화 통화이후에는 하나씩 단서를 추적해가면서 원인을 찾기 시작했다.
얼마전 인계받은 C 시스템은 K8S 기반의 AI실습을 위한 컨테이너 환경을 제공하는 시스템이다.
해당 시스템에서는 고급기술인 ISTIO를 일부 기능만 부분적으로 사용하고 있었다.
ISTIO (처음에는 어떻게 읽어야할지 몰랐다. 이스티오 라고 읽는다)
마이크로서비스 아키텍쳐에서 많이 사용되는 서비스 메쉬로, 서비스 메쉬란 각 서비스 별로 envoy 같은 proxy서버 (sidecar)를 배치하여 메쉬 네트워크를 구성함으로써 서비스와 네트워크 계층에 대한 독립성을 보장하는 역할이다. ISTIO를 사용하면 서비스 구현단계에서 네트워크 계층을 고려할 필요가 없다는 장점이 있다.
ISTIO는 많은 기능이 있지만 C 시스템에서는 service discovery 용도로 사용되고 있었다. 생성되는 서브 도메인을 통해서 각각의 container와 연결되는 구조이다. 이 때의 연결은 virtual service라는 kubernetes object를 이용해서 특정 서브 도메인으로 접근하면 특정 service object로 전달된다.
슬랙 에러 알림을 자세히 보면 가장 마지막 줄은
Unexpected: [object Object] 로 나와있어서 어디에서 문제가 발생하는지 처음에는 알수없었다.
그래서 그 다음으로 현재 사용중인 데이터독의 대시보드 화면을 통해
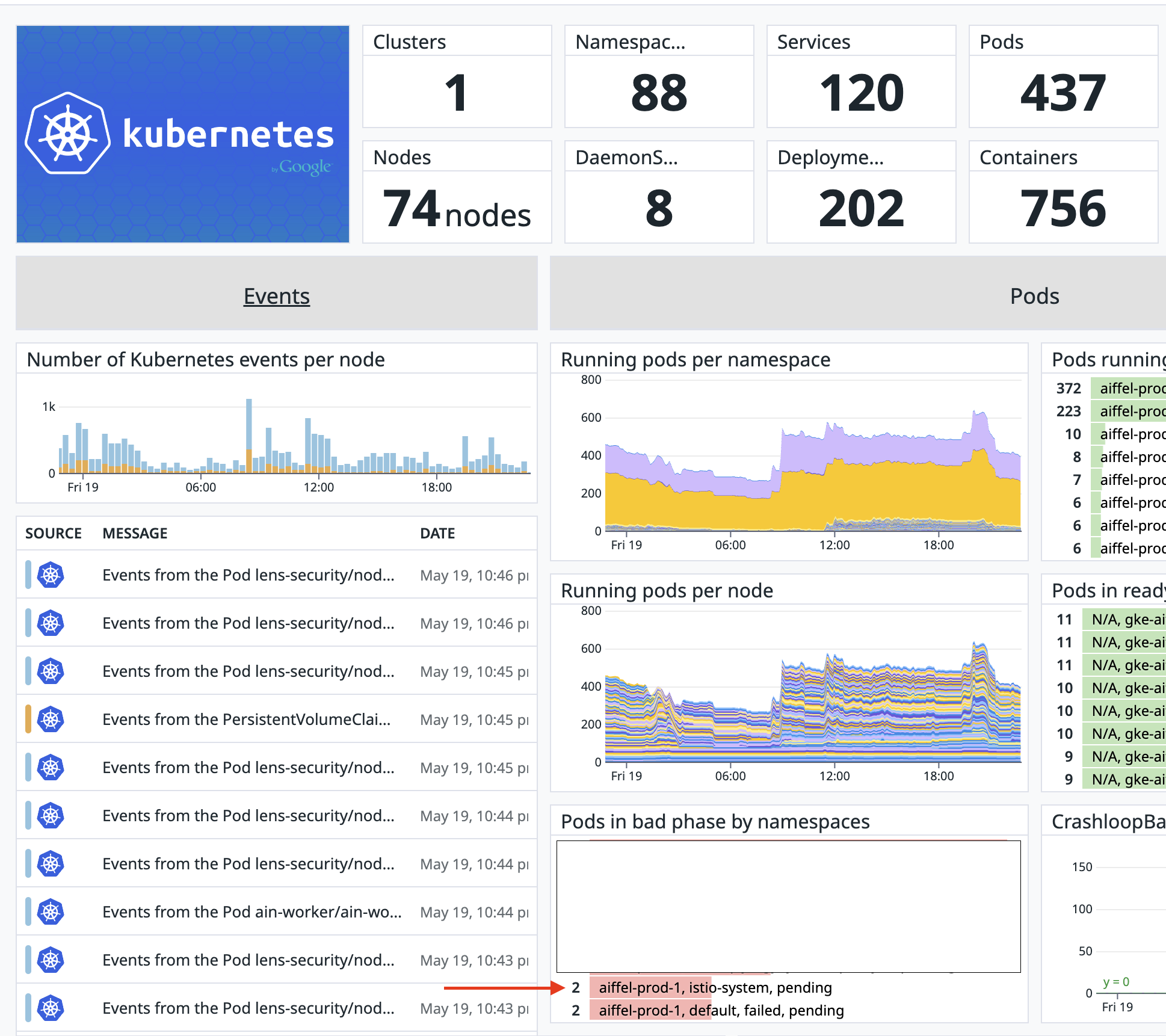
Pods in bad phase by namespaces 부분에서 모니터링 이후 일반적으로 볼수없었던
istio-system, pending 상황을 확인하게되었다.
대부분의 컨테이너가 정상이었으나 istio-system Namespace의 container만 pending 이었다.
데이터독의 Logs 메뉴에서 istio-system Namespace의 error만 필터링 해보니 오후9시 이후로 에러가 급증함을 알수있었다. 원인을 찾아서 해결하고 이렇게 정리글을 작성할수있음에 감사하다. 정말.
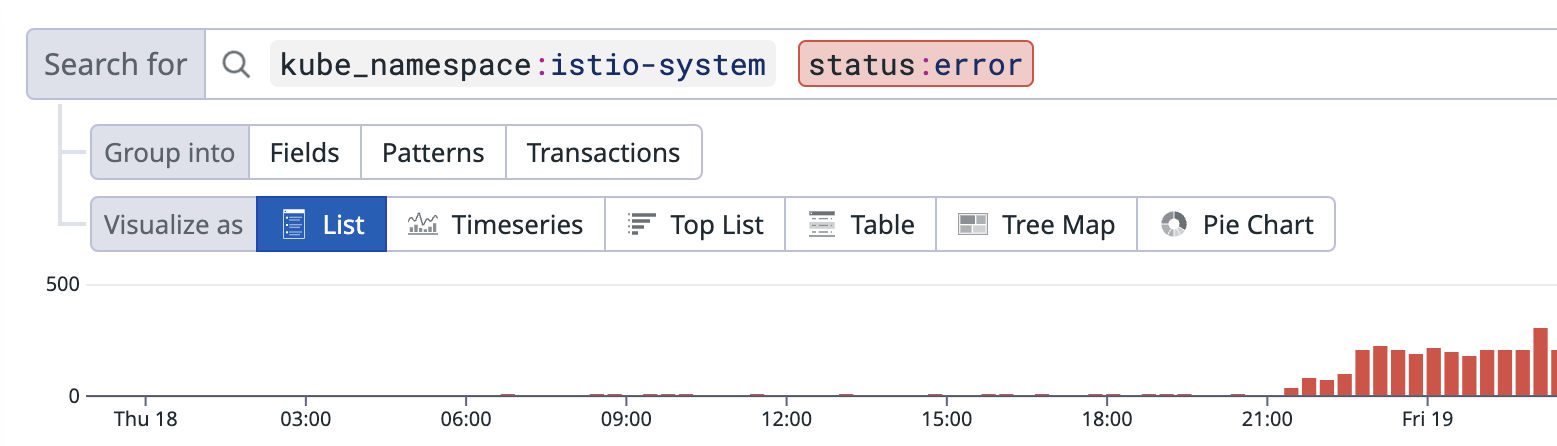
해당 화면에서 아래영역은 상세로그를 확인할수있는데 에러의 내용은 아래와 같았다.
2023-05-18T22:25:31.578411Z warning envoy config StreamSecrets gRPC config stream closed: 14, upstream connect error or disconnect/reset before headers. reset reason: connection termination
2023-05-18T22:25:31.576813Z warning envoy main caught SIGTERM
2023-05-18T22:25:20.848480Z warning envoy config Unable to establish new stream
2023-05-18T22:25:18.132632Z warning envoy config StreamSecrets gRPC config stream closed: 14, connection error: desc = "transport: Error while dialing dial tcp x.x.x.x:15012: connect: connection refused"
connection termination, connect: connection refused 와 같은 내용이 있었다.
무슨이유에서인지 커넥션을 맺지 못하고 있었고,
kubectl logs istiod-xxx-xxx -n istio-system
로그를 조회해보면 아래 내용이 확인되었다.
2023-05-18T23:38:28.218058Z error Patch webhook failed: the server could not find the requested resource
2023-05-18T23:38:28.702041Z error k8s.io/client-go@v0.18.3/tools/cache/reflector.go:125: Failed to list *v1beta1.Ingress: the server could not find the requested resource
2023-05-18T23:38:35.869238Z error k8s.io/client-go@v0.18.3/tools/cache/reflector.go:125: Failed to list *v1beta1.ValidatingWebhookConfiguration: the server could not find the requested resource
급한대로 평소 k8s 를 잘알고 있는 형한테도 현재의 상황을 간단히 설명하고 어떻게 접근하면 좋을지 의견을 구했다.
돌아온 대답은 istio control plane과 admission controler 상태를 확인해보라는 내용이었다.
현재 GKE를 사용하고 있는데 데이터독의 메뉴들을 확인해보았을때 control plane정보를 찾을수 없었다. 데이터독 검색을 해보니 documentation에 아래 내용이 나와있었다.
On other managed services, such as Azure Kubernetes Service (AKS) and Google Kubernetes Engine (GKE), the user cannot access the control plane components. As a result, it is not possible to run the
kube_apiserver,kube_controller_manager,kube_scheduler, oretcdchecks in these environments.
GCP GKE 메뉴에 들어가 관측가능성 탭에서 제어영역 , prometheus 사용설정을 활성화시켰고 조금 기다리자 수집된 메트릭정보들이 하나 둘씩 보이기시작했다.
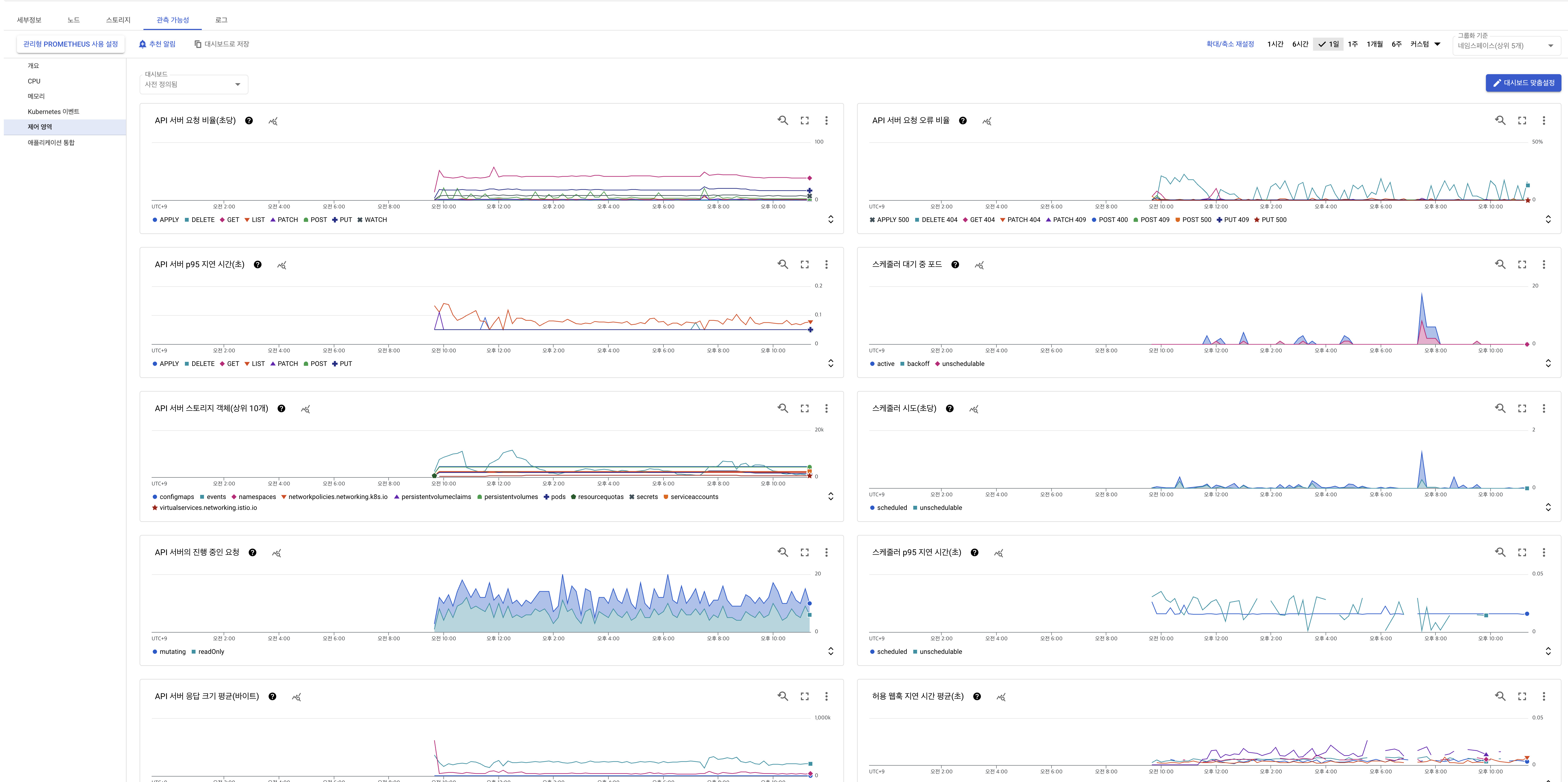
여기까지 왔을때 사실 더 판단하기가 어려웠다. 다른것들은 정상이고 istio만 pod이 죽어있는 상황이 그것도 오후 8시를 기준으로 갑자기. 별다른 기능이 반영된것도 아니고 또 클러스터 수정이 있지도 않았다.
운영환경만 문제가 발생하고 있었고 개발환경은 정상이었기에
약간 지푸라기라도 잡는 심정으로 Lens 를 통해 개발환경과 운영환경의 istio를 비교하기 시작했다.
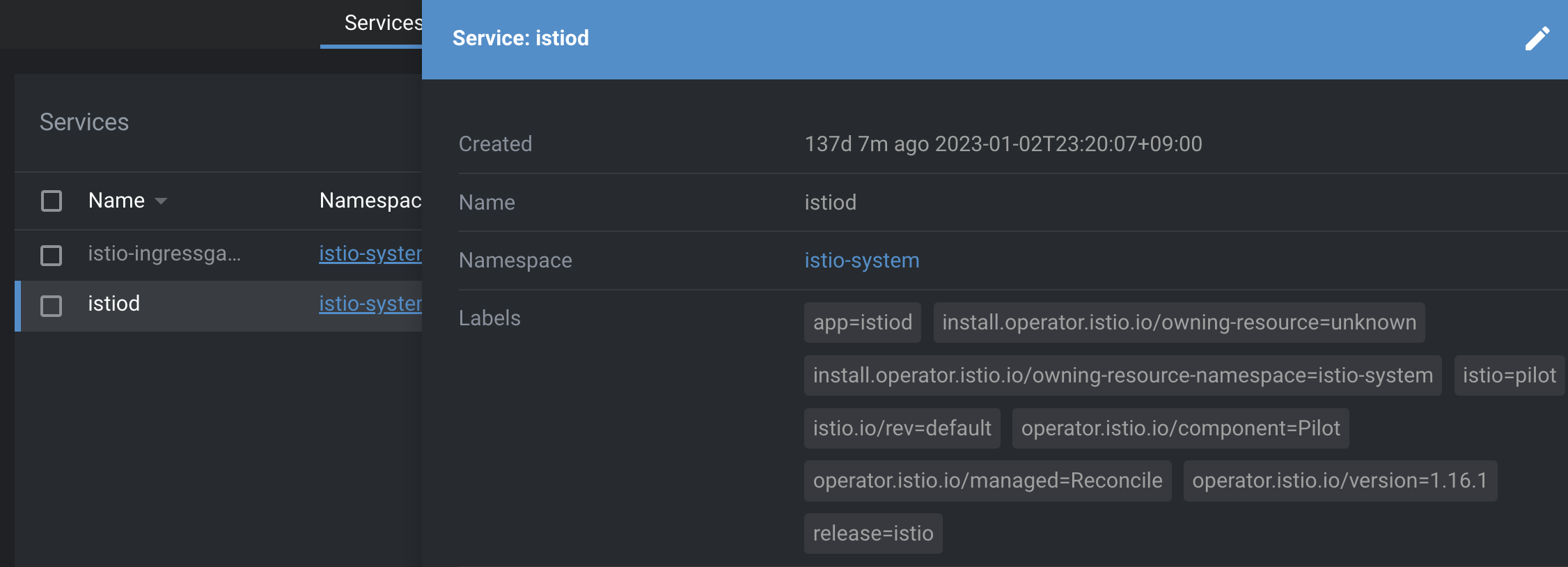
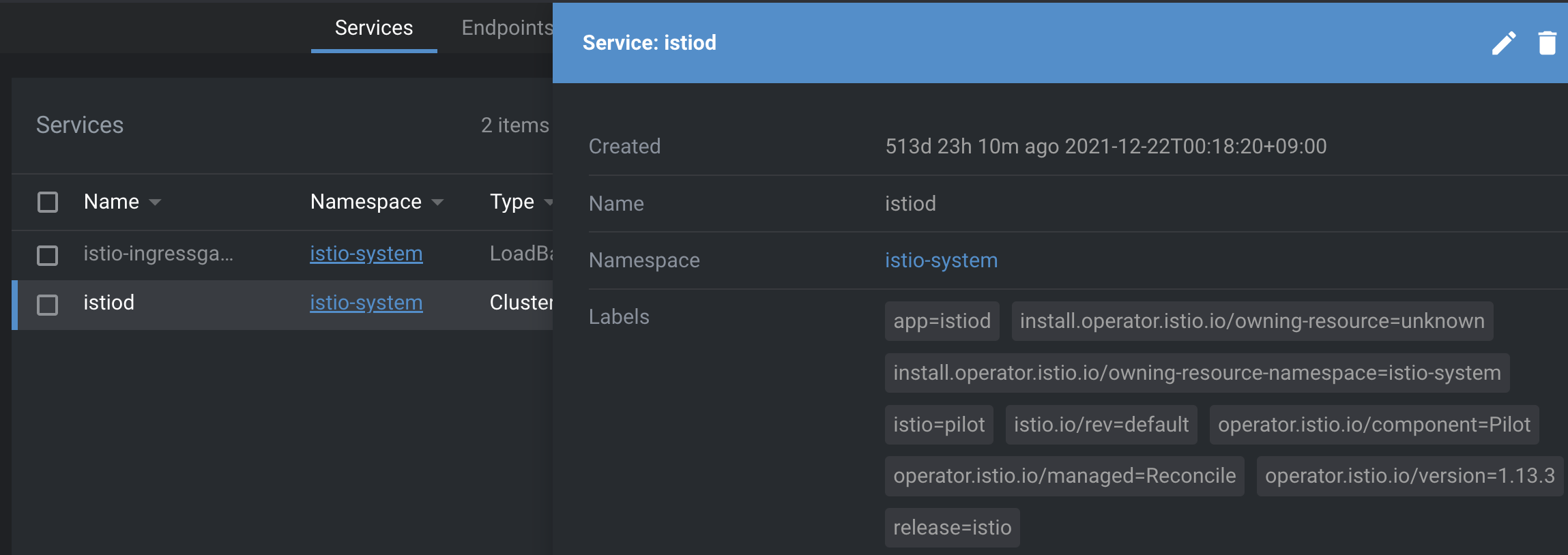
혹시 어떤 부분이 다른지 찾았는가?
위가 개발환경의 istiod 이고 아래가 운영환경의 istiod 이다. istio의 version에 주목해야한다.
현재 화면은 운영환경의 버전을 업데이트한 이후이고 장애상황 당시에는 istio 의 버전이 무려 1.7.4 이고 개발환경의 istio 버전은 1.16.1 이었다.
흠.. 버전 차이가 나도 너무 많이 나는 느낌이 들었다.
istio 깃허브 에서 확인한 최신버전은 1.17.2 이고 4월 5일에 릴리즈가 된 것을 확인했다.
그리고 istio documentation에서 Supported Releases 페이지 내용을 확인하고 있었는데
다음의 문구가 눈에 들어왔다.
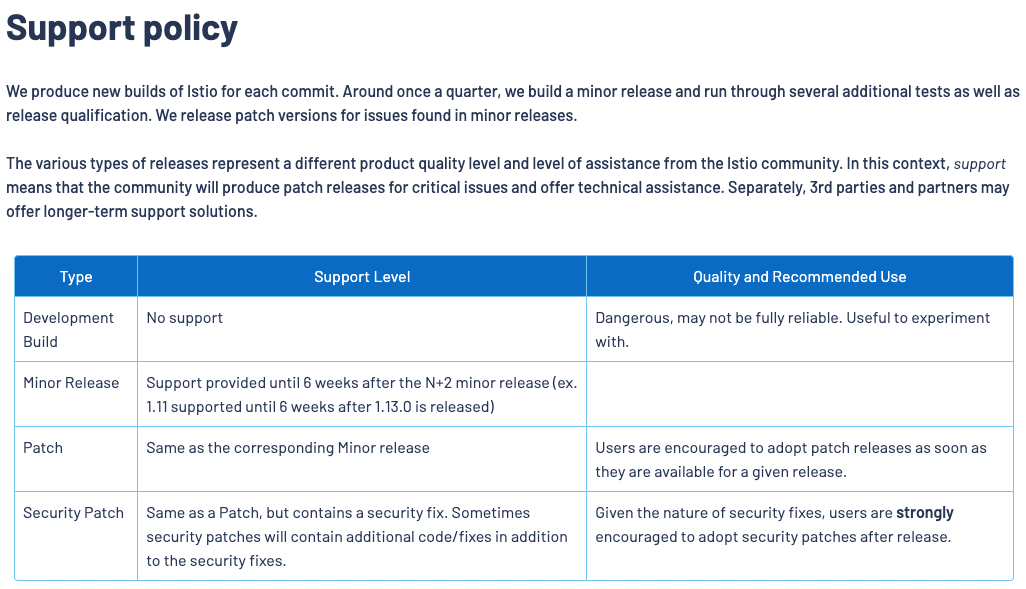
Support provided until 6 weeks after the N+2 minor release (ex. 1.11 supported until 6 weeks after 1.13.0 is released)
새로운 버전이 나오고 6주(?!)가 지나면 이전버전들에 대한 지원도 하나씩 사라진다.
공교롭게도 1.17.2가 릴리즈된지 6주의 시간이 지났음을 달력을 보고 확인할수 있었고
그럼 운영환경의 1.7.4 istio 버전이 문제의 원인일수 있겠다는 생각이 들기 시작했다.
재빨리 운영환경의 istio 버전 업그레이드를 어떻게 해야할지 방법을 찾기 시작했다.
istio 버전 업그레이드는 canary 방식 또는 in-place 방식, helm을 이용한 방식이 있었다.(링크)
운영환경이 정상이고 사용자들이 현재 사용중인 상황이라면 안정적으로 canary 방식이 맞겠으나 현재 컨테이너 생성이 되지않고 사용자들이 서비스에 불편을 겪고 있는 상황이라
빠르고 확실히 진행할 수 있는 in-place upgrades를 진행하게되었다.
https://istio.io/latest/docs/setup/upgrade/in-place/
istio in-place 업그레이드는 아래순서로 진행.
-
새 Istio 릴리스를 다운로드하고 디렉터리를 새 릴리스 디렉토리로 변경
-
업그레이드할 클러스터를 가리키는 Kubernetes 구성이 있는지 확인
$ kubectl config view
- 업그레이드가 사용 중인 환경과 호환되는지 확인
$ istioctl x precheck

GCP 클러스터에 클라우드 쉘로 연결해서 위 cmd를 입력했을때 별다른 이슈가 없다면 No issue found ~ 메시지가 나온다.
- 다음 명령을 실행하여 업그레이드를 시작:
$ istioctl upgrade
명령을 실행하면 몇 가지 검사를 수행한 후 istioctl에서 계속 진행할지 여부를 확인하라는 메시지가 표시됩니다.
업그레이드 당시에는 엔드포인트와의 통신이 실패로 나오고 있었지만 무시하고 계속 진행을 선택했다.
-
istioctl은 Istio 컨트롤 플레인과 게이트웨이를 새 버전으로 제자리에서 업그레이드하고 완료 상태를 표시.
-
istioctl이 업그레이드를 완료한 후, Istio 사이드카가 있는 모든 파드를 재시작하여 Istio 데이터 플레인을 수동으로 업데이트:
$ kubectl rollout restart deployment
다행히도 해당작업으로 운영환경의 istio 버전은 1.13.3 으로 업그레이드 되었다. 물론 해당버전도 end of life 기간이 이미 지나서 지원하는 k8s 버전 업그레이드와 발맞춰서 업그레이드를 진행할 예정이다. 정상적으로 운영중인 상황이기에 이번과는 다르게 canary 방식으로 진행해볼 생각
istio 버전 업그레이드와 동시에 container가 정상으로 바뀌었고 수많은 에러도 잦아들었다.

내부 시스템 테스트를 빠르게 진행해봤을때 이상없는 것을 확인하고 전체 공지로 장애상황이 해결되었음을 알릴 수 있었다.
짧지만 강하게 istio를 알게되었다. istio관련된 자료들이 워낙 없다보니 잘 정리된 블로그들과 자료들을 찾아가면서 확인해볼 생각이다.
이번 장애로 몇가지 잊지말아야할 교훈이 있다면,
-버전관리의 중요성. 사용중인 주요 라이브러리들의 버전을 주기적으로 체크하고 최신 릴리즈 버전과 많이 차이나는 버전으로 운영하지 않도록 하자.
-기본으로 돌아가 k8s 구성요소 각각의 역할과 상호관계를 잘 파악해두자. 컨트롤 플레인이 중요한 부분임에도 데이터독으로 모니터링 되지않고 있음에도 GCP cloud 메뉴에서 모니터링을 연결해두지 않았었다.
-장애상황에서는 정확한 원인의 파악도 중요하지만 빠른 해결도 중요하다
아주 잠시지만 istio 업그레이드를 어떻게 할지 고민을 하고 있었는데 동료와 이야기해서 빠른 장애해결을 위해 in-place 방식 으로 진행한것은 잘한일인 것 같다.
이후에 canary 방식 으로 진행하게 된다면 그때에는 다시 진행된 상황을 정리해보겠다.
모니터링은 평소의 정상적인 상황에서는 그 중요성을 간과하기 쉽지만 장애상황에서 빠르게 원인을 찾고 조치를 취하는데 나침반 역할을 해주는 것 같다.
running 중인 pod의 초록색 불들이 새삼 고맙게 느껴지는 긴 하루였다.