관리자메뉴에서 엑셀다운로드 버튼을 클릭했을 때 아래와 같은 에러가 발생하고 있었다. ERR_FAILED 504
504 에러가 발생한 원인을 찾아보고 어떻게 해결할수있을지 방법도 함께 제안해보겠다.
현재 시스템의 백엔드 구성은 Nginx, Gunicorn, python Django 로 되어있다.
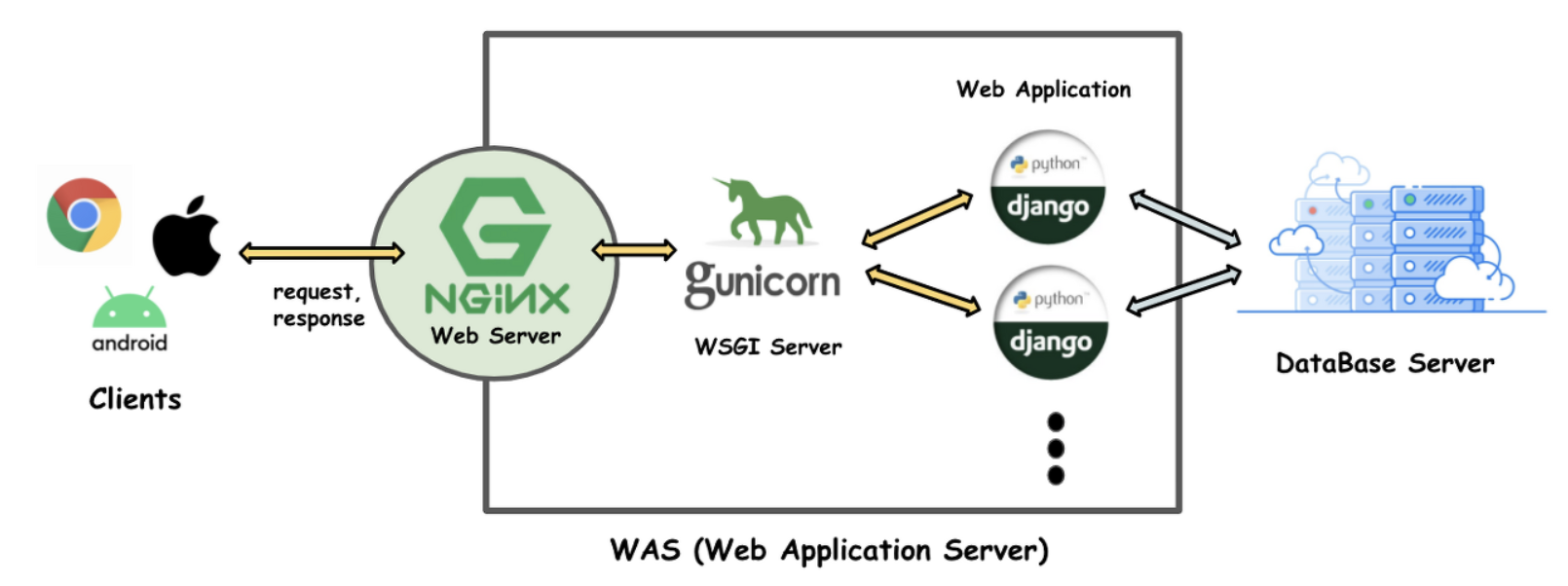
504 Gateway TIme-out 에러는 여러 경우에 발생할 수 있지만 지금의 경우는 4300건 정도의 데이터를 엑셀파일로 다운로드 받는 과정에서 발생했다.
조금 상세히 과정을 살펴보면,
- 클라이언트(웹 브라우저)가 파일 다운로드를 요청
- 요청이 Nginx 프록시 서버에 도달. Nginx는 요청을 받아들이고 다운스트림 서버(Gunicorn)로 전달
- Gunicorn은 요청을 받아 Django 어플리케이션에 전달
- Django 어플리케이션은 요청을 처리하고 필요한 파일을 생성 또는 검색. 이 과정에서 대량의 데이터를 처리해야하는 경우, 시간이 오래 걸림
- Django 어플리케이션은 처리된 결과를 Gunicorn 에 반환
- Gunicorn은 결과를 Nginx에 반환
- Nginx 는 클라이언트에게 응답을 반환하려고 시도
504 에러는 일반적으로 서버가 요청에 응답하는데 너무 오래 걸리고 프록시 서버(Nginx) 또는 부하 분산 장치가 연결을 닫을 때 발생한다. 이 문제를 해결하는 방법에는 여러 가지가 있는데 이 중 3가지 정도를 소개하려 한다.
첫번째 방법은 timeout 설정을 늘리는 것이다.
Nginx 설정중 ‘proxy_read_timeout’ 를 늘리거나 gunicorn 의 timeout 을 늘린다.
필자의 경우는 두 개값 모두 300 으로 되어있었다.
#nginx.conf
location / {
proxy_pass http://your_upstream_server;
proxy_read_timeout 300s;
}
#docekr파일에서 web server cmd 부분
gunicorn --timeout 300 your_project.wsgi:application
두번째 방법은 다운로드 건수를 제한하는 방법이다
API 상으로 페이지 매김 또는 필터링을 구현해 사용자가 전체 데이터 세트가 아닌 작은 데이터 청크를 한 번에 다운로드할 수 있도록 한다. 이는 Django 에 내장된 페이지 기능을 사용
from django.core.paginator import Paginator
def your_view(request):
data = YourModel.objects.all()
paginator = Paginator(data, 1000) # Limit to 1000 records per page
page = request.GET.get('page')
data_page = paginator.get_page(page)
# Serialize and return data_page as a response
세번째 방법은 StreamingHttpResponse 를 활용
StreamingHttpResponse 을 사용하면 응답을 메모리에 모두 로드하지 않고 chuck 로 스트리밍해서 대량의 데이터를 다운로드할 때 메모리 사용량을 줄이고 성능을 개선하는데 도움이 될수 있다.
대신 HttpResponse에서 StreamingHttpResponse으로 변경할 때는 다음 사항을 고려해야한다
- 문자열이나 바이트형 객체를 콘텐츠로 전달하는 대신 데이터 청크를 생성하는 제너레이터 함수를 전달
- 응답에 적절한 콘텐츠형식과 파일을 지정
from io import BytesIO
from django.http import StreamingHttpResponse
class YourViewName:
# ...
def data_stream(self, wb):
# Save the workbook to a temporary buffer in chunks
buffer = BytesIO()
wb.save(buffer)
buffer.seek(0)
# Read and yield the content in chunks
while True:
chunk = buffer.read(4096) # You can adjust the chunk size
if not chunk:
break
yield chunk
def post(self, request, *args, **kwargs):
data = self.list(request, page=False).data
wb = xlwt.Workbook(encoding="utf-8")
ws1 = wb.add_sheet("sheet1")
# ... (Rest of the code remains the same)
for row in rows:
row_num += 1
for col_num in range(len(row)):
ws1.write(row_num, col_num, row[col_num], font_style)
# Instead of saving to response, use the data_stream generator with StreamingHttpResponse
response = StreamingHttpResponse(self.data_stream(wb), content_type="application/ms-excel")
response["Content-Disposition"] = f"attachment; filename=TestUserList.xls"
return response
기존 post() 메서드는 아래와 같이 작성되어있었으나
response = HttpResponse(content_type="application/ms-excel")
response["Content-Disposition"] = f"attachment; filename=TestUserList.xls"
# 중략...
wb.save(response)
return response
StreamingHttpResponse를 사용하면서 wb를 param으로 받아 임시버퍼에 저장하고 그 내용을 chunk로 출력하는 새로운 제너레이터 함수 data_stream() 를 추가했다.
-
아래는 StreamingHttpResponse Django Documentations 주요내용
WSGI 에서 StreamingHttpResponse는 보통 대용량 CS 파일을 생성한다던지 응답을 생성하는 데 시간이 너무 오래 걸리거나 메모리를 너무 많이 사용할 때 콘텐츠를 스트리밍 하는 것
하지만 WSGI 기반의 Django 는 수명이 짧은 요청을 위해 설계되어 응답을 스트리밍하면 응답의 전체 기간 동안 작업자 프로세스가 묶이게 되고 이로 인해 성능이 저하될 수 있다.
ASGI에서 서비스를 제공할 때 StreamingHttpResponse 는 I/O를 기다리는 동안 다른 요청의 서비스를 중단할 필요가 없다. 따라서 콘텐츠 스트리밍을 위한 장기 요청과 롱폴링, 서버 전송 이벤트와 같은 패턴을 구현할 수 있다. ASGI에 따르면 StreamingHttpResponse는 데이터를 클라이언트에 전송하기 전에 전체 콘테츠를 반복하지 않아야 하는 경우에만 사용해야한다. 콘텐츠에 액세스할 수 없기 때문에 많은 미들웨어가 정상적으로 작동하지 않는다. 예를 들어 스트리밍 응답을 위해 Etag 및 Content-Length 헤더를 생성할 수 없다.
그럼 다시 3가지 방법중에 어떤 것을 선택했을까?
1번째 방법은 이미 적용되어있었고 2번째 방법은 백엔드 로직만 수정할게 아니라 프론트단에서도 사용자가 사용하는 기능수정이 고려되어야 한다.
3번째 방법은 HttpResponse → StreamingHttpResponse로 간단히 변경되는 것은 아니고
제너레이터 함수추가와 함께 WSGI 에서 Django를 사용하고 있다면 조금 고려할 게 있었다.
다시 처음으로 돌아가서 4000건 이상 데이터를 다운로드 받는게 빈번하게 발생하는 일인지 생각해보고
기존 메서드에서 개선할수 있는 부분은 없을지 확인해보는데,
def post(self, request, *args, **kwargs):
data = self.list(request, page=False).data
post() 메서드는 엑셀다운로드를 위해 self.list() 를 통해 기존 페이지네이션 처리되던 것을 전체 데이터를 일괄로 가져오고 있었다.
평균계산 및 가공처리가 되는 부분이어서 list() 메서드 자체와 serializer에서 수정할수 있는 부분이 있을 것 같아서 조금 더 최적화 작업을 진행해보기로 했다.
504 Gateway Timeout 을 해결하기 위해 왜 그리고 어디서 504 Gateway Timeout 가 발생하는지
python Django 에서는 어떤 해결방안이 있는지 확인해보았다.
결론은 다양한 방법을 알고 적용하는 것도 중요하지만 기본으로 돌아가서 사용하는 로직에서 개선할 게 없는지를 확인하는게 중요하다는 걸 새삼 깨닫는다.