Day1 세션들 중 직접 듣지는 못하였으나 관심있는 세션들을 슬라이드 내용을 중심으로 요약정리했습니다
초등학생 AI모델 고등학교 보내기: Continual Learning으로 지속적으로 성장하는 AI 시스템 만들기
정현희, 박경호/ 쏘카
1. Background and Motivation
- 지속적으로 성장하는 AI 시스템을 도입해야 하는 이유와 challenges
- 우리는 최고 성능을 달성한 모델을 배포하고, 특정 테이블에 Inference 결과를 적재
- 현실에서 동작하는 AI 시스템은 End-User의 피드백을 받아 지속적으로 업데이트
- 현실에서는 학습시킨 모델을 지속적으로 업데이트 해야하고, 몇 가지 Challenge가 있음
- 1) 모델의 Faulty Predictions
- 2) Task와 관계없는 데이터
- 3) 새로운 Label이 추가되는 피드백
- 일반적인 AI Model의 LifeCycle
- 보다 더 효율적으로 모델을 재학습시킬 수 있는 아이디어 소개
- Task와 무관한 데이터를 Isolate
- 효율적으로 Scientis가 요구하는 데이터를 수집
- 새로운 Label을 포함해 AI모델을 재학습
2. Continuous AI System
- 카셰어링 도메인에서의 Continual Learning 도입 필요성과 문제정의
- 카셰어링 도메인에서는 유저가 촬영한 차량 이미지가 주어졌을 때 차의 상태를 분류하는 Task
- 지속적으로 성장하는 AI 시스템의 각 Component의 학습방법
- OOD(Out of Distribution Detection) 을 이용해 Task와 관계없는 데이터를 Isolate
- 필요한 데이터를 손쉽게 찾아주는 Data Retriever를 이용해 레이블링 효율성을 높임
3. Continual Learning
- Continual Learning과 관련된 이전 연구들 및 한계점
- scratch부터 학습하지 않고 추가된 데이터만 학습
- 기존에 구축해둔 운영 환경에서 weight파일만 교체
- Offline External Validation 통과시 배포 자동화
- Catastrophic Forgetting을 막기 위한 다양한 시도들
-
Catastrophic Forgetting이란?
치명적 망각은 인공 지능(AI) 및 머신 러닝(ML) 모델이 한 가지 작업에 대해 학습한 후 새로운 작업에 대해 재학습할 때 발생하는 현상입니다. 이 과정에서 모델은 첫 번째 작업에서 학습한 내용을 잊어버려 원래 작업과 새로운 작업 모두에서 효율성이 떨어질 수 있습니다.
치명적 망각을 이해하려면 뇌를 AI 모델이라고 생각해 보세요. 자전거 타는 법을 배웠다고 가정해 봅시다. 그런 다음 자동차 운전법을 배우려고 하면 뇌가 이제 운전이라는 새로운 과제에 집중하기 때문에 균형 잡는 법과 같은 자전거 타기의 세세한 부분까지 잊어버릴 수 있습니다.
AI와 머신러닝에서 치명적인 망각은 특히 새로운 작업을 지속적으로 학습하고 적응해야 하는 모델의 경우 심각한 문제가 될 수 있습니다. 하지만 이를 방지하기 위한 몇 가지 시도가 있습니다. 다음은 몇 가지입니다:
정규화: 이 접근 방식은 모델의 손실 함수에 이전 지식을 유지하도록 장려하는 페널티 항을 추가하는 것입니다. 이렇게 하면 모델이 이전 작업에서 학습한 정보를 보존하도록 인센티브를 받게 됩니다.
탄력적 가중치 통합: 탄력적 가중치 통합(EWC)은 새 작업이 해당 가중치에 미치는 영향을 제한하여 모델의 중요한 가중치를 보호하는 방법입니다. 이 접근 방식은 이전 작업의 중요한 가중치를 효과적으로 ‘고정’하여 새로운 지식으로 덮어쓰기에 덜 민감하게 만듭니다.
잊어버리지 않고 학습하기: 잊어버리지 않고 학습(LwF)은 이전 작업에서 새로운 작업으로 지식을 이전하는 기법입니다. 이 접근 방식을 사용하면 모델이 두 작업에 대해 유사한 출력을 생성하도록 장려하는 추가 손실 용어를 추가하여 이전 지식을 유지하면서 새로운 작업을 학습할 수 있습니다.
동적 아키텍처: 치명적인 망각을 방지하는 또 다른 방법은 이전 작업에 영향을 주지 않고 새로운 작업에 적응할 수 있는 동적 아키텍처를 사용하는 것입니다. 예를 들어, 연구자들은 새로운 작업이 도입될 때 신경망의 크기를 키워 네트워크가 이전 지식을 유지하면서 새로운 정보를 학습할 수 있도록 하는 방법을 개발했습니다.
이는 AI와 ML에서 치명적인 망각을 방지하기 위한 수많은 시도 중 일부에 불과합니다. 연구자들은 이 문제를 해결함으로써 이전 지식을 잃지 않고 새로운 작업을 지속적으로 학습하고 적응할 수 있는 모델을 개발하고자 합니다.
- 과거에 제안된 Continual Learning 방식의 한계점
- 이전 Task에서와 현재 Task 사이에 Knowledge Sharing 이 비효율적
- Buffer에 들어가는 Discriminative Cue가 늘어나면 메모리 이슈 발생
- Brain-inspired Continual Learning Method: Lightweight Prompt Learning with General Representation (LPG)
- 인간은 새로운 Task를 학습할 때마다 새로운 저장공간을 만들지 않는다
- 별도의 Buffer와 같은 새로운 저장공간을 만들 필요는 없을 것이다
- 여러 Task에 공통 적용되는 지식은 장기기억에, 특정 Task에 한정된 지식은 단기기억에 해당
- Benchmark Scenario에서의 실험 (Fine-grained, Coarse-grained)
- 여러 Taske들에 공통적으로 작용하는 뉴런이 존재함을 확인
- Ablation Study
4. Bussiness Impact & Deployment
- 서비스 적용 시의 Performance Gain
- Software Architecture for Deployment
- Continuous AI System을 통해 해결한 카셰어링 도메인의 오퍼레이션 문제들
5. Demo
6. Lesson Learned
지금까지 이런 검색은 없었다. 이것은 검색인가 추천인가 - 네이버 스마트블록 개인화 검색
한상규, 옥슬기, 최형주/ NAVER Search
1. 스마트블록 개인화 검색 소개
- 스마트블록 개인화 검색이 가져올 변화
- 통합 검색 서비스에 사용자의 검색 의도 및 컨텐츠 소비 성향 분석에 기반한 개인화 검색 기술 적용 유저에 따라 개인화된 맞춤형 검색 결과 제공
- 스마트블록 : 통합 검색 랭킹의 단위를 세분화
- 컬렉션이란?
- 뉴스, 지식iN, 쇼핑, 장소 등 동일한 컨텐츠 종류 내에서의 검색 결과
- 개인화된 맞춤형 랭킹의 대상으로써 컬렉션은 다소 포괄적인 단위
- 스마트블록이란?
- 주요 검색 의도 및 세부 주제까지 타게팅하는 검색 결과 단위
- 사용자가 원하는 검색 결과를 더 디테일하게 제공 가능
- 컬렉션이란?
- 검색 페이지의 랭킹 영역 구분 - 정답형, 탐색형, 반응형
- 정답형: 검색어에 대한 확실한 답을 알고 싶어”
- 탐색형: 검색어와 연관된 다양한 정보를 탐색하고 싶어
- 반응형: “클릭한 문서에 대해 더 상세한 정보를 알고 싶어
-
개인화 검색 시스템 구조 소개
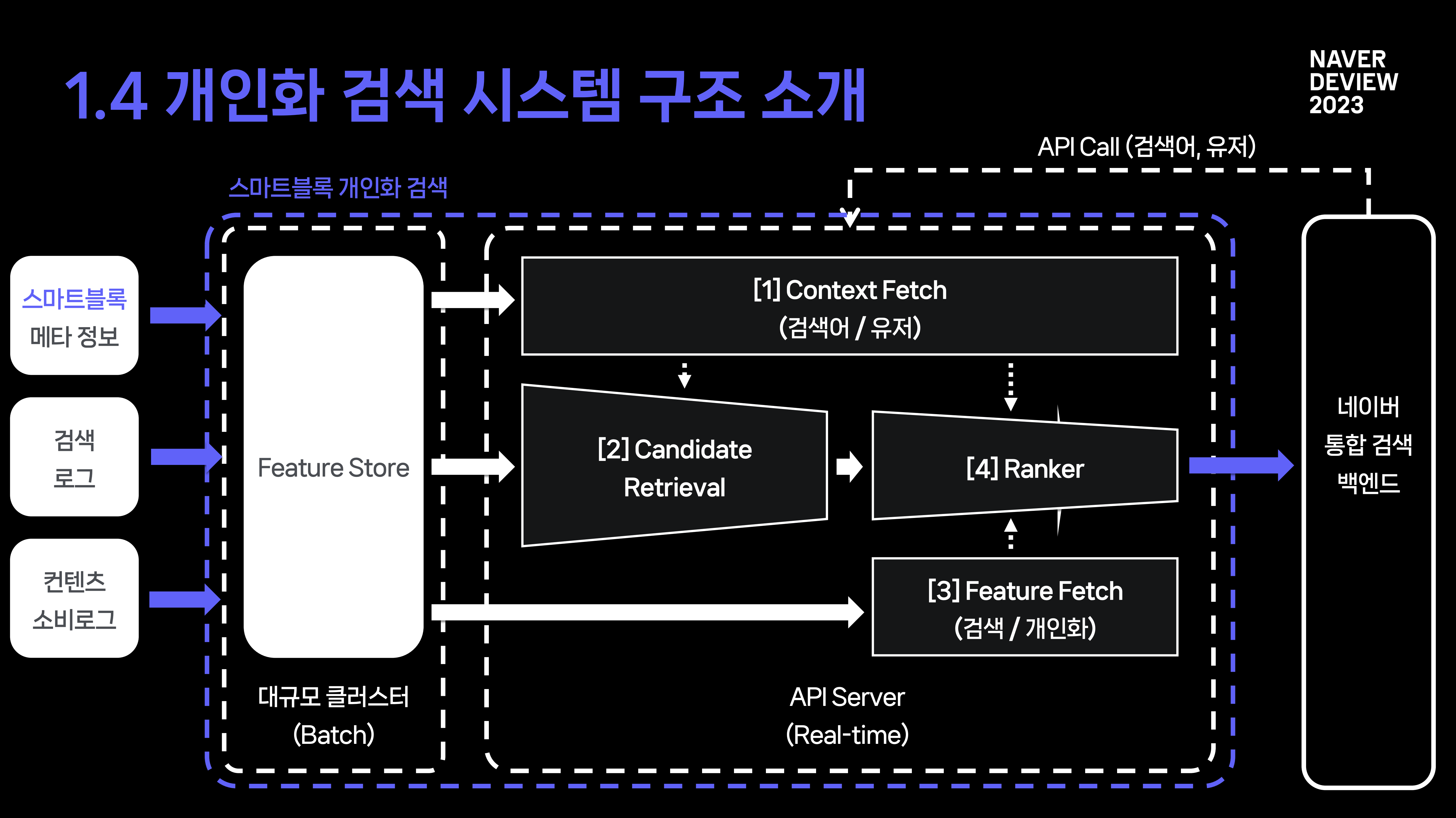
2. Ranking 모델
- Ranking 모델 개요
- Implicit Feedback 기반 학습 데이터셋
- 유저가 특정 검색어를 입력한 뒤 검색 페이지에 노출된 n개 블록 중
- 클릭 발생 (label = 1)
- 클릭 미발생 (label = 0)
- 랭킹 모델 s 를 parametrize 하는 방식 - linear, MLP, DCN, DASALC
- DCN (Wang et al., WWW ‘21) 모델
- DASALC (Qin et al., ICLR ‘21) 모델
3. Retrieval 모델
- 개인화 검색을 위한 Retrieval task
- 검색어 à 의도 단위 블록 생성 (토픽, 장르)
- 다양한 검색어-블록 Retrieve 필요 (recall)
- 여러 Retrieval 모델을 함께 사용하기
- SPLADE (SIGIR ‘22, Naver Labs Europe) 모델
4. 검색 Feature
- 연관 검색 Feature
- 함께 소비된 검색어 Pair의 연관 Score
- Feedback Feature
- Bandit Feature
5. 개인화 Feature
- 개인화 Feature 개요
- 관심사를 검색으로 표현한 상태에서 더 구체적인 개인화된 의도파악 필요
- 초개인화 추천문제 해결하기 위한 Feature 개발
- M3 (Tang et al., WWW ‘19) 유저 임베딩
- 유저 개인별로 다양한 Feature를 활용하여 유저를 나타내는 고차원 Dense 벡터
- 유저 History 기반으로 생성 & 세밀한 취향 반영가능하기에 초개인화에 중요
- 최근 본 문서와 그 이전 문서에 얼마나 영향을 미쳤는지 간접적으로 측정
- Short-term, Long-term을 위해 여러 기간으로 다중 임베딩 시 문제점
- 유저마다 K개 임베딩을 유지하기에 Feature Store 부하 존재함
- 이전 영향도를 개인별로 다르게 반영하는 하나의 유저 임베딩 필요
- M3 유저 임베딩 (Multi-temporal-range Mixture Model) 개발
- 과거 데이터 기반으로 미래에 볼 문서를 잘 예측 하도록 학습
- 실시간 개인화
- 유저가 최근 검색한 검색어에서 중요 키워드를 점수화 (최근&자주 검색할수록 높은 점수
- 유저별 중요 키워드가 존재하는 스마트블럭들을 점수화 하여 상위권으로 랭크
- 개인화 검색결과 만족도 분석
- 클릭 엔트로피가 높은 검색어에서 개인화 검색 효과적
- 클릭 엔트로피가 높은 검색어 예
- 제주실내가볼만한곳, 베트남쇼핑리스트, 갈비찜레시피
- 클릭 엔트로피가 낮은 검색어 예
- 지하철요금, 사과칼로리, 은행업무시간
- 관심분야가 다양한 유저에게 개인화가 더 효과적
6. 마무리
네이버 스케일로 카프카 컨슈머 사용하기
이동진 NAVER Platform Labs
1. 카프카 컨슈머: 내부 동작
- 카프카 컨슈머 간략 소개
- Topic
- 1개 이상의 Partition으로 분할, 1개 이상의 Replica로 복제된 log 자료 구조
- Client
- Producer: 쓰고자 하는 Topic Partition의 맨 끝에 record를 추가
- Consumer: 읽어오고자 하는 Topic의 Partition에 저장된 record를 순차적으로 읽어 옴
- Topic
- 컨슈머 그룹
- 같은 ‘group.id’ 설정값을 가진 Consumer들은 하나의 Consumer Group을 이룬다.
- 같은 Consumer Group에 속한 Consumer들이 Topic에 속한 Partition들을 나눠서 읽는다.
- Consumer Group == “논리적인 Consumer”
- 거대한 Consumer 하나가 전체 Topic 내용을 읽어들이고 있는 것처럼 보인다.
- 파티션 할당
- 오프셋 커밋
- 파티션 할당 자세히 살펴보기
- 그룹 코디네이터 + 컨슈머 그룹 리더
- Consumer Group Coordinator
- Consumer Group에 변경이 생겼는지 탐지
- TopicPartition에 변경이 생겼는지
- Consumer Group Leader와 나머지 Consumer들간의 communication 중개
- Consumer Group Leader
- 현재 구독중인 topic의 파티션들을 consumer들에 할당
- Consumer Group Coordinator
- 동작 순서: ‘성급한 할당’
- 할당 알고리즘
- Range Partitioner
- Round Robin Partitioner
- 한계: 클라우드 환경을 감안하지 않고 개발됨
2. 클라우드 환경에서 카프카 컨슈머 사용하기
- 클라우드 환경에서 발생하는 문제 해결하기
- 물리적 장비의 자원을 여러 pod가 나눠서 씀 (multitenancy)
- Pod Rescheduling이 일상적임
- session.timeout.ms 설정
- “Consumer 프로세스가 Broker와 신호를 주고받지 않고도 리밸런스를 발생시키지 않는 최대 시간”
- 단순 network hiccup 때문에 Partition Rebalance가 발생하는 사태를 방지
- group.instance.id 설정
- 정상적 재시작 이전에 할당되어 있던 파티션들을 다시 할당
- 단순 pod 재시작 때문에 Partition Rebalance가 발생하는 사태를 방지
- rack.id 설정
- “Consumer가 위치한 AZ를 알고 있고 해당 AZ에 leader replica와 동기화된 상태를
- 유지하고 있는 follower replica가 있다면, 여기서 읽어올 수 있게 하자!”
- partition.assignment.strategy 설정
- 성급한 할당
- 점진적, 협력적 할당
- 설정 변경 + 무중단 업그레이드하기
- 한계
- 네이버의 클라우드 환경
- 기본적으로 제공되는 기능만으로는 해결이 불가능하다!
- 본질적인 원인
- “’Rack’이 가리키는 바가 지나치게 애매모호하다.”
- ’데이터센터’? ’물리적 서버 랙’?
- 의미하는 바가 ‘네트워크’ 보다는 ‘전력’ 에 기울어짐
- ”Partition Assignor가 rack 정보를 고려하지 않는다.”
3. Navercorp Partition Assignor
- 발상
- 네이버의 해법: RackAwareRangeAssignor
- 1단계: leader replica의 rack에 따라 할당
- 2단계: follower replica의 rack에 따라 할당
- 3단계: 남은 Partition들을 순차적으로 할당
- group.instance.id 자동 인식
- rack.id 자동 인식
- 협력적 할당
- 성능
4. 결론
상황에 맞는 취향 장소 발견하기. HyperLocal 추천 시스템 A to Z
전영환/ NAVER Search
1. 지역 관점의 장소 추천 시스템
- 1.2 사용자들이 새로운 장소를 발견하기 어려운 이유
- 검색어가 떠오르지 않는 경우
- 취향 장소를 찾지 못한 경우
- 탐색의 상황에 맞지 않는 경우
2. HyperLocal Personalization의 단계들
- 무엇을 추천하여 장소를 발견하게 할 것인가?
- 어떤 방식으로 추천할 것인가?
- 지역의 다양한 Trend를 추천하자
- 내가 속한 그룹의 인기에 기반하여 추천하자
- 사용자의 취향을 깊이 있게 이해하여 추천하자
- 사용자가 놓인 상황까지 이해하여 추천하자
3. HyperLocal Personalization의 다양한 Representation Learning 기술들
- Recommendation Next POI with Heterogeneous Domain : RelatedPOI2vec
- 특정 업체를 다음에 방문할 만한 장소를 추천하자
- 방문 장소와 유사한 성격을 지니는 장소들을 주로 탐색함
- Optimization with Joint Representation Learning : Global-POI2vec
- 취향 장소와 가장 유사한 특성을 지닌 장소를 추천하자
- Understanding User Behaviour with Graph Deep Learning : FollowSAGE, VisitSAGE, History2vec
- 나와 유사한 행동을 보이는 사용자를 추천하고
- 그 사용자들을 통해 취향 장소를 발견하게 하자
- FollowSAGE : User Homogeneous Graph를 기반으로 한 GraphSAGE 기반 모델
- VisitSAGE : User-POI Bipartite Graph를 기반으로 한 PinSAGE 기반 모델
- History2VEC : 최근 방문 POI 기반 Deep Learning 모델
4. HyperLocal Personalization을 위해 하고 있는 것들
- Understanding Intent with Multimodality : 이미지, Text 등을 종합적으로 고려해서 추천 해보자
- “Multimodality에 기반한 검색 의도를 이해하여 추천해보자
- Optimize Search Context : 장소 탐색의 실시간 Context를 반영해보자
5. 사용자들은 실제로 추천 서비스들을 어떻게 이용하고 있을까? (a.k.a User Satisfaction Evaluation)
- RQ1. 추천 기술이 사용자 취향을 깊이 있게 이해하여 추천하고 있는가? (a.k.a Accuracy)
- RQ2. 사용자들은 얼마나 많은 SME들을 발견하고 있는가? (a.k.a Novelty)
- RQ3. 사용자들을 실제로 얼마나 만족을 하고 사용하고 있는가? (a.k.a Retention)
- 지역의 Visual Trend를 추천해보자!
- Real Time Context를 이해하여, 추천을 최적화하자!”