Day1 만 신청완료되었고 여러 세션들 중 관심있는 세션들을 듣고 내용을 요약정리했습니다. 각 세션 끝에는 간단히 느낀점과 생각들도 정리하였습니다.
네이버 검색은 어떻게 나보다 더 내 의도를 잘 아는가? : AiRSearch 반응형 추천
임희재/ NAVER Search
네이버 통합검색
사용자 의도에 적합한 검색 결과를 제공하기 위한 노력,
사용자 의도를 이해하는 방법은 검색어를 기반으로 의도를 예측하게 되는데 2021 deview 발표자료 - 사용자 의도와 취향을 이해하는 네이버 통합검색
탐색 과정에서 클릭하는 문서를 기준으로 사용자 관심사와 검색의도가 구체화된다.
사용자 의도를 예측한 반응형 추천은
사용자의 행동을 바탕으로 의도를 이해하고, 반응형으로 컨텐츠를 빠르게 제공하여 새로운 발견의 기회를 제공한다.
반응형 문제를 정의하면
네이버 통합검색에서 문서를 소비하고 돌아온 사용자들에게
input
사용자의 행동기반정보 : 검색어, 클릭한 문서, 사용자의 취향 정보 등
output
추천문서
반응형 문제 특징(1)
narrow down (특정주제에서 한단계 더 나아가 세부주제로) side by side (특정주제 A에서 관련없는 주제 B로)
반응형 문제를 풀기 위한 3가지 방법
- Intent query
클릭한 문서의 제목에서 핵심 의도를 표현하는 키워드 찾기
ColBERT 아키텍쳐 응용
[1] “Colbert: Efficient and effective passage search via contextualized late interaction over bert”, SIGIR, 2020.
학습데이터 아이디어 -> 검색 세션 로그 를 이용해서 학습 데이터를 구축
- Intent Walker
그래프 기반으로 사용자 의도에 맞는 문서 추천하기
유저가 클릭한 문서를 시작점으로 랜덤 워크 수행
[2] “Pixie: A system for recommending 3+ billion items to 200+ million users in real-time”, WWW, 2018.
유저가 클릭한 문서를 시작점으로 label propagation 수행
GCN 임베딩 학습
- User Preference
유저의 취향에 적합한 문서를 추천하기
추천 문서에 대한 long-term 의 세대성별 선호도를 ranker 의 feature 로 추가
개인의 short-term 관심사 기반한 개인화 랭킹 연구 중
반응형 서비스 개발을 위한 꿀팁!
1.문제를 작게 정의하기
막연하게 풀고 싶은 큰 문제를 구체적이고 해결 가능성이 있는 작은 문제부터 시작
사용자 의도 : narrow down 만 있다고 가정
대상 문서 : 여행 등 일부 카테고리 한정
작은 문제의 장점
작은 문제부터 시작해서 문제 확장 -> 각 문제를 풀수 있는 적정기술을 개발 -> A/B Test -> 사용자 피드백으로 새로운 문제 정의
2.학습데이터 잘 구축하기
학습데이터 정의
(q1, d1) -> 후보 d2의 적합도 [0, 1] or [1,2,3,4]
개선 아이디어 CTR 역전되면 negative
검색에는 rank bias 존재
3.ABTest 잘 활용하기
플랫폼을 이용하여 최종 검증된 모델을 서비스 적용
4.지표 모니터링하기
CTR, 체류시간, LCR (마지막 클릭 비율) 등을 모니터링
서비스 운영 결과
인플루언서 반응형 문서 추천의 경우
1년 운영: 서비스 초기 대비 CTR 30% 증가
사용자 만족도 상승을 위한 지속적인 모델 개선
Personal insights
해당 발표의 연사분과 진행하는 워크샵에 선정되어서 개인적으로는 사전에 따로 블로그 글로 정리를 하고 갔었다. 조금더 내용을 긴장하면서 보아서인지 검색이라는 전혀 새로운 분야가 조금은 낯설지않고 재미있게 느껴졌다. 중간에 나오는 개발 꿀팁은 반응형 서비스 뿐만 아니라 새롭게 AI서비스 개발을 준비중인 사람들이면 꼭 숙지했으면 한다.
따로 참석한 워크샵에선 검색/추천에 관심있는 분들과 발표자를 비롯한 회사분들이 오셔서 간단히 자기소개를 하고 사전에 남긴 질문에 대해 이야기하는 시간을 나누었다. 아래는 워크샵에서 이야기나눈 주제들이다.
Q. ChatGPT 가 검색을 어떻게 바꿀 것인지?
아직 신뢰성 문제가 남았다, AI 전체를 바꿀것이라 확신이 들기도한다
단기간에 바꿀수있는건 적을 것이다
Q. 네이버 에어서치 서비스의 향후 발전 계획이 있나요?
동일한 검색결과가 아니라 개인별로 서로 다른 검색결과 제공하는 중
Q. 어떤 데이터를 다루고, 어떻게 시스템을 구축하였는지?
반응형 검색의 경우 1일 1번정도 주기로 오프라인 데이터를 업데이트한다.
연산량을 사전에 계산해서 어느정도로 서비스를 허용할지 범위를 정하고자
Q. 유저 임베딩의 효과를 어떻게 검증했는지?
반응형검색에서는 효과가 없어서 서비스 되지는 못했음
어떤 임베딩이 좋은지?
Q. 평가를 어떻게 하는지?
눈으로 보며 듣는 음성기록, 클로바노트 서비스의 웹 기술 톺아보기
임대현, 이은성/ NAVER Cloud
임대현 - 2015년에 deview 발표 DEVIEW 2015 - 네이버 효과툰 구현 이야기
클로바노트 서비스란?
-
- 19 Release 되었음, 눈으로 보며 듣는 음성 기록 CLOVA Note
v2 에선 웹에서도 녹음이 가능하도록 업데이트 될 예정
클로바노트의 웹 기술들
2.1 오프라인 지원
next.js + next-pwa + workbox
- workbox 란? PWA의 캐싱(caching) 기능을 편하게 구현할 수 있도록 지원되는 표준 PWA 라이브러리. [sw-precaching], [sw-toolbox] 라이브러리가 지원하던 기능들을 통합하여 제공한다.
오프라인에서 기능을 제공하기 위해 local storage와 lndexedDb를 사용,**
CRDT : Conflict-Free-Replicated Data Types(yorkie(https://yorkie.dev/)) 기술을 사용
- update after deploy
브라우저에 따라 24시간 대기가 필요함 업데이트 시
v1.2 부터는 5분 간격으로 web worker 를 이용한 버전 체크, 수동 업데이트 진행, 강제 업데이트 로직 추가, 에러시 SW 제거 및 해당버전 재설치 방지
API Wrapper 와 서비스 워커를 분리해서 XHR 분기를 추가
2.2 반응형 UI -> UX
디바이스가 다양해지고 있음,
modernizr 를 사용해 사용자의 마우스/터치 이벤트 분기 mouse 경우 hover시 체크박스 노출, touch 경우 체크박스 기본 노출
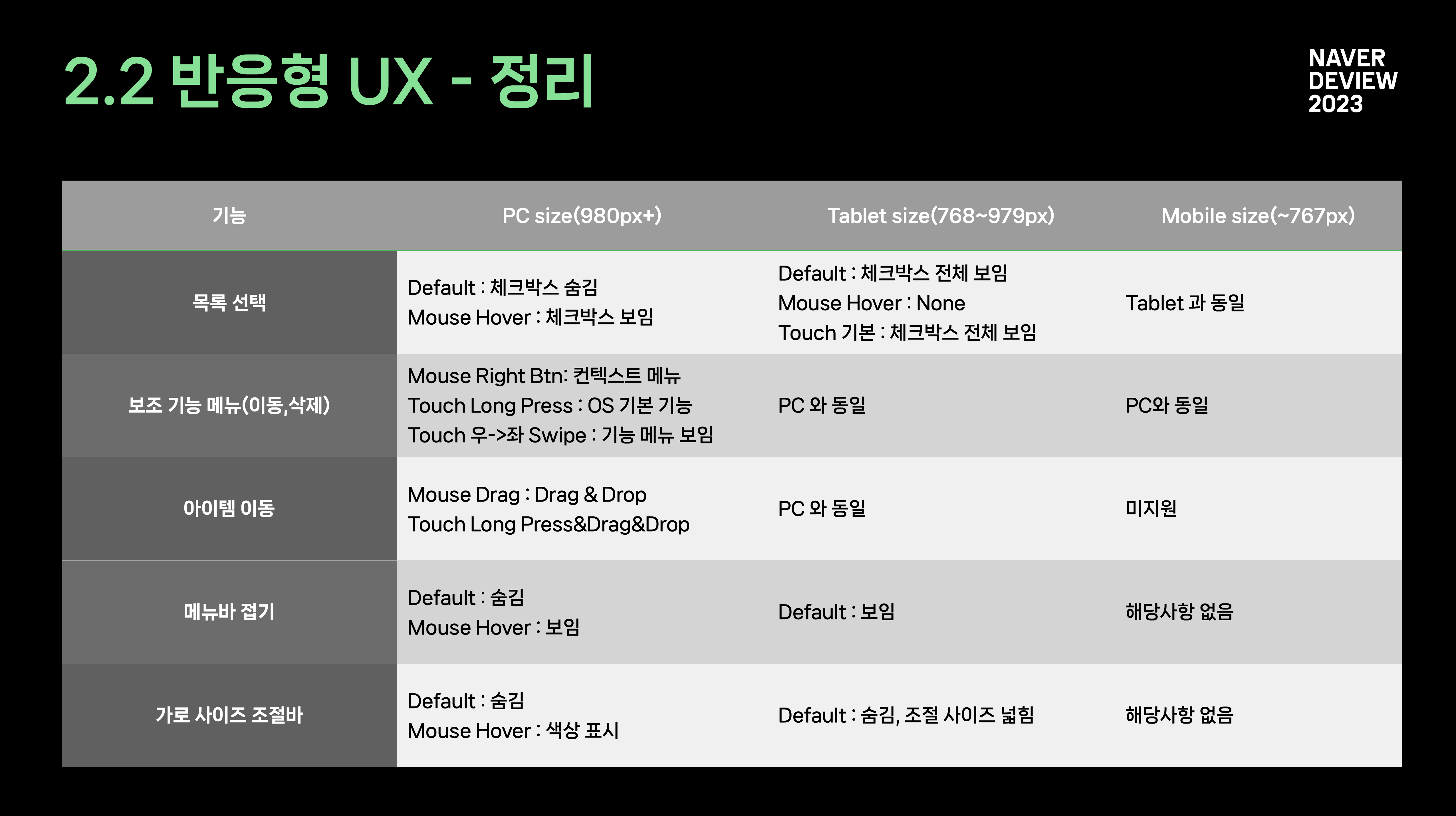
2.x 클로바 노트의 웹 기술들
2.3 zoom 서비스 연결
줌에서 제공하는 기본 API들을 활용해 poc로 시작했다가
줌이 끝난 후 정리하는 간접적인 기능에서, 회의죽 직접적인 도움 기대
실시간으로 가져오는 기능 구현을 위해 고려한 것들
라이브스트림/ RTMP node media server 백엔드 서버를 구축함
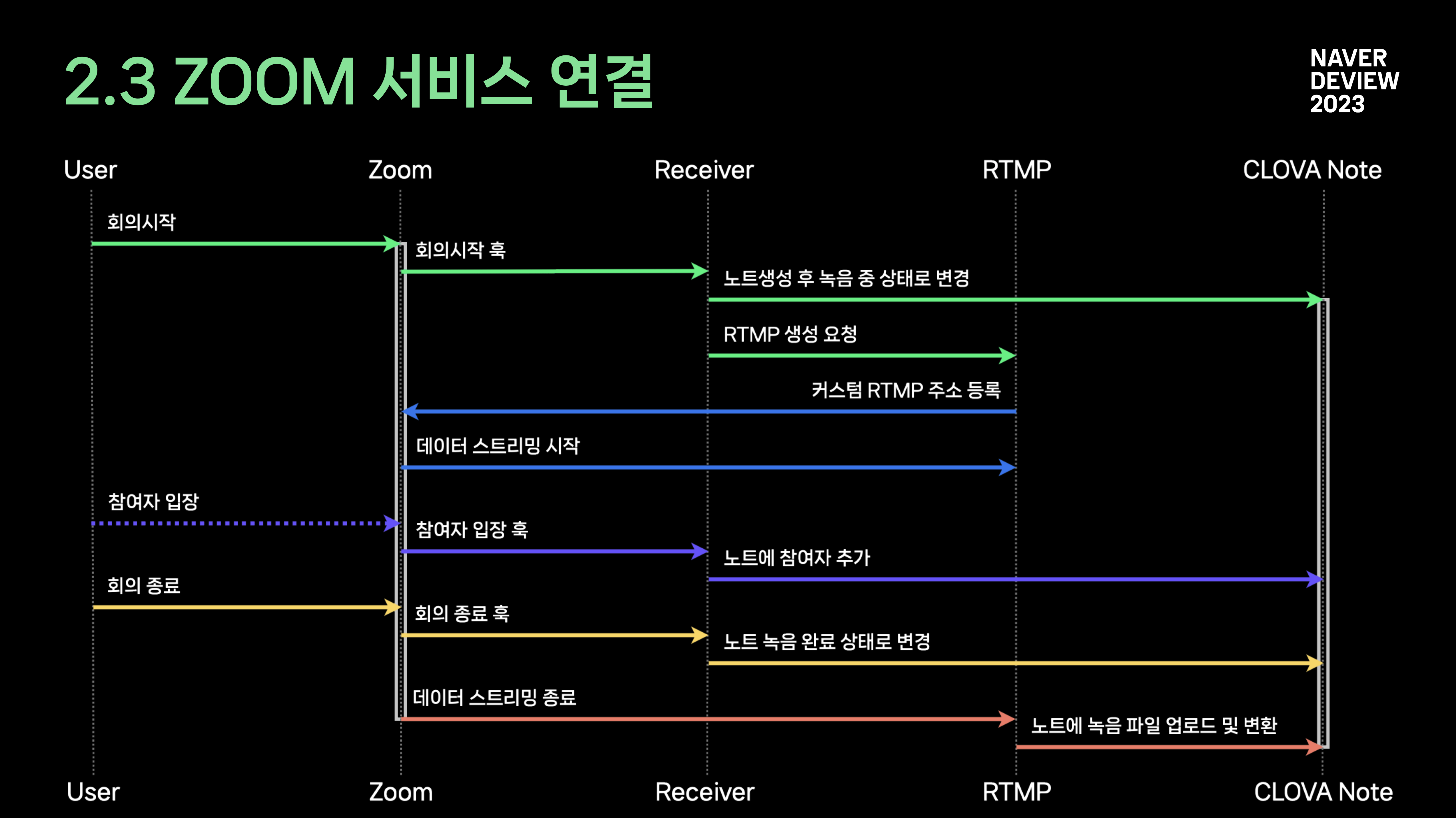
- 예외처리
웹훅 API, RTMP 타이밍 문제
프로세스가 진행되는 동안 주기적으로 REST API 더블 체크
하나의 언어로 일관된 개발
BFF(Backend for Frontend) 서버 개발
2.4 모노레포
도메인별로 통합된 하나의 모노레포를 사용함
기술적인 장점에는
- 반복적인 환경셋팅, 코드 중복 최소화
- 효율적인 의존성 관리
- 단일 이슈 트래킹
- 각자의 역할에 집중된 작은 패키지들
기술적 장점 +
- 린트외의 팀 규칙
- 신규 입사자의 컨텍스트 파악
- 적극적인 리뷰 문화
사용하는 툴
- yarn의 workspace 기본 기능만 사용
복잡해지는 모노레포 환경은 지양
빌드 캐싱은 docker 활용
모노레포에 더욱 적합한 언어 Javascript, Typescript
앞으로도 계속 사용될 레포 전략
2.5 아토믹 디자인 패턴
shared ->
아톰의 더 이상 분해되지 않는 것으로는 애매한 기준
재사용하지 않아도 되는 부분까지 나눠줘야하는 불필요함
UI 라이브러리에서 제공하는 수준을 아톰이라고 정의
UI에 집중되어있는 아토믹 패턴
-
브라우저 테마의 위치는?!
-
businesses 폴더를 만들어서 재사용성이 필요없는, UI가 없는 로직 컴포넌트 위주로
2.6 리코일
React 18 동시성의 장점을 그대로
react18 렌더링 스케쥴러
로드 작업이 빠르다면 로딩 화면 스킵
동시성을 구현하는 기술 - 심흥운
직접 접근하여 사용할때의 문제
- 프로젝트가 커져갈수록 복잡해지는 종속성
- 디버깅의 어려움
- 컴포넌트의 복잡함이 리코일로 이동
격리된 도메인별 리코일
- 아톰, 셀렉터에 직접 접근 없이 훅으로만 연결
- 순서가 필요하다면 비지니스 컴포넌트 사용
3 웹팀의 개발 문화
개발 효율화
운영 효율화
세계 최고의 기술력 지향
감성 스크럼, 매주 스크럼을 진행한다, 처음엔 좋았다가 형식적으로 변해가는. 로봇이 아니고 사람이다
코드리뷰 영어로 커뮤니케이션 중
2주 단위 스프린트
목표 = 미달성 + 달성 + (추가달성)
Personal insights
클로바 노트를 몇번 사용해보아서 잘 만들었다고 생각하고 있었다. 이렇게 직접 만든 분들의 이야기를 들어보면 편하게 사용하고 있는 기능이 어떠한 고민들을 거쳐서 나왔는지 알수있어서 좋은 것 같다.
2분다 발표가 능숙하셨고 프론트에 집중된 내용들이었지만 같은 팀의 프론트개발자 분들이 이야기하던걸 들은게 있어서 조금더 집중해서 듣게되었다. 반응형 UX 정리내용이라던지 시퀀스 다이어그램은 추후에 개발할때도 참고가 될것같아 장표를 직접 캡쳐해두었다.
임대현 발표자님이 DEVIEW에 참석하고 몇년뒤에 DEVIEW에서 발표하고 또 다시 발표한 것처럼
나도 언젠가는 DEVIEW에 데뷔할 날을 꿈꿔본다.
검출과 인식 모델을 하나로? : challenge 우승 OCR 서비스 모델 새 출시!
길태호, 서석민/ CLOVA OCR text vision
기존 Clova OCR 서비스 모델
OCR 서비스 모델 2 stage(검출+ 인식) 구조
2 stage 모델의 문제점 1: 검출이 실수하면 인식 또한 실패
-> recognizer 가 crop 된 이미지가 아닌 이미지 전체를 보면 맞출 수 있지 않을까?
문제점 2: 2개의 image backbone
-> image backbone
문제점 3: 검출기를 update 하면 인식기도 새로 학습
-> 서비스 유지 보수 측면에서 어려움
-> 2개의 모델을 한번에 학습할 수 없을까?
글자 탐지와 인식이 한번에 된다고?
2.1 e2e OCR의 장점
일반적인 end to end OCR 방법론
검출과 인식을 한번에 학습 -> 더 쉬운 유지 보수
image backbone을 공유 -> 2번의 image backbone forward를 거칠 필요가 없음
DEER의 장점
기존 모델은 어떤 단어를 인식할때에 feature pooling 활용
각 단어에 대한 RoI feature 를 인식기에 전달하는 방식
검출 실수에 robust
DEER는 단순히 위치 짚어준다.
image feature + 글자위치 짚어주기
ROI feature 만 보여주는 것이 아닌, Image 전체를 인식기한테 보여준뒤 짚어준 점을 보게된다.
DEER 뜯어보기
DEER: Detection-agnostic End-to-End Recognizer
- Location Head
multi scale feature 로부터 text 검출
DEER
- Text Decoder
Deer 가 짚어준 위치 + whole image feature (not pooling)
Image 전체가 아닌 reference point 근처의 몇몇 point 만 활용하여 attention
핵심 Idea:
OCR 분야에서 검출과 인식을 학습하기
“전체 Text 검출학습은 충분히 가능하나 전체 Text 인식 학습은 어려운 문제이다” 에 대한 추가자료
전체 텍스트 감지와 인식은 모두 OCR(광학 문자 인식) 분야에서 중요한 작업입니다. 전체 텍스트 감지는 이미지나 문서에서 모든 텍스트 영역의 위치를 식별하는 작업이며, 전체 텍스트 인식은 해당 영역의 문자를 인식하고 전사하는 작업입니다.
전체 텍스트 감지는 잘 연구된 문제이며 딥러닝 기반 객체 감지 알고리즘과 같은 최신 기술을 통해 높은 정확도를 달성했지만, 전체 텍스트 인식은 여전히 어려운 문제로 남아 있습니다. 그 주된 이유는 글꼴, 크기, 방향, 스타일이 다양하고 이미지에 노이즈, 왜곡, 폐색이 존재하기 때문에 텍스트의 모양이 매우 가변적이기 때문입니다.
전체 텍스트 인식 성능을 개선하기 위해 취할 수 있는 몇 가지 접근 방식이 있습니다:
데이터 증강: 한 가지 접근 방식은 입력 이미지의 무작위 회전, 크기 조정, 왜곡과 같은 데이터 증강 기술을 사용하여 학습 데이터의 양과 다양성을 늘리는 것입니다. 이렇게 하면 모델이 다양한 조건에서 텍스트를 인식하는 방법을 학습하는 데 도움이 될 수 있습니다.
전처리: 또 다른 접근 방식은 입력 이미지에 이진화, 노이즈 제거, 데스큐잉과 같은 전처리 기술을 적용하여 텍스트 영역의 품질과 일관성을 개선하는 것입니다.
언어 모델링: 전체 텍스트 인식은 n-그램, 언어 모델, 사전 기반 방법과 같은 언어 모델링 기법을 활용하여 가능한 문자 시퀀스의 공간을 제한하고 인식 정확도를 개선할 수 있습니다.
하이브리드 접근 방식: 많은 OCR 시스템은 인식 정확도를 높이기 위해 언어 모델링과 결합된 딥러닝 기반 특징 추출을 텍스트 인식에 사용하는 등 여러 가지 접근 방식을 조합하여 사용합니다.
요약하자면, 전체 텍스트 인식은 텍스트의 모양이 매우 다양하기 때문에 OCR에서 어려운 문제입니다. 하지만 데이터 증강, 전처리, 언어 모델링, 하이브리드 접근 방식과 같은 기술을 활용하면 인식 정확도를 높이고 고품질의 OCR 결과를 얻을 수 있습니다.
해결책으로는 학습시 샘플링한 대상만 인식(짚어주기를 통해서)
얼마나 빠르고 가볍다구요
기존 모델 대비 Inference Time 및 Memory 비교
검출 실수와 rotation에 강인한 DEER
새 모델은 이것도 할수 있어요
Character Detection
단어보다 자세하게: 문자 단위 검출
단어 단위 검출 뿐만 아니라 문자 단위 검출
기존 recognizer 에 기능 추가
장점: recognizer 끝단에 regressor 만 추가 -> 가벼움
Data 문제
Char 위치에 대한 annotation은 cost가 매우 비싸다
5%의 word 만 char annotation 을 갖고 있음
Pseudolabeling 활용
1.Labeled data로 teacher model 학습 - char 검출이 가능한
2.Teacher model은 weakly-labeled data에 대하여 pseudo-label 생성 3.최종 모델은 labeled data와 weakly-labeled data를 모두 활용하여 학습
문서 구조 추출
단어보다 큰 단위: line과 paragraph 검출
line/paragraphj 에 대한 location head 추가 (Db 기반)
라인단위, 문단단위를 추가하더라도 글자단위 인식률의 성능이 내려가지 않음
국제 OCR challenge 1등
4.1 OOV Challenge
주제 : Out of Vocabulary Scene Text Understanding
Out of Vocab: 학습 때 전혀 보지 못했던 words
실제 시나리오에 더 적합한 task
4.2 model development
7개의 public 데이터셋을 가지고 진행
DEER 의 text 많은 이미지 학습 방법
OCR 분야에서 검출과 인식을 학습하기
- Data statics
텍스트 개수에 상관없이 모델을 잘 학습해야 함
DEER 의 짚어주기와 고정수량 text 학습으로 안정적
- Training Data Ratio
- 텍스트 개수에 비례하게 세팅
- 인식기가 모든 Text data를 잘 학습하도록 구성
COCO dataset
Noisy 한 Location Annotation 에도 인식기 학습 가능
Our experience
다국어 관련
option1
검출기에서 다국어를 검출하지 않게 함 (오직 영어 검출기) • 인식기는 영어만 인식 가능
option2
검출기는 영어 + 다국어 모두 사용
인식기에서는 영어 이외 ‘unk’ 태그로 처리
서비스 배포를 위해
DEER Model 경량화 encoder
Inference Time 분석
Transformer encoder 에서 56% 로 가장 많은 시간을
왜 Encoder 에서 가장 많은 시간이 필요할까?
DEER는 Deformable Attention으로 key/value를 sparse하게 가져가서 시간복잡도 O(S)
sequence 자체가 길기 때문에 여전히 많은 시간이 소요됨
encoder 에서 가장 긴 sequence 인 stride4 feature를 query 에서 줄이기
1안: stride4 feature를 query에서 완전 제거
2안: stride4 feature를 sparse하게 1/4만 query 제거
encoder 경량화 모델과 기존 모델 비교
성능하락은 CLEval score 기준 0.006으로 크지 않음
encoding time 70% 감소, 메모리 사용량 33% 감소
decoder
Text 개수별 Decoding 시간 비중은 계속 증가
Decoder 속도 증가 방법
Decoding 시 배치 크기를 늘려, 한번에 많은 텍스트를 Inference
배치 크기를 1024까지 증가시켜 총 디코딩 시간을 73% 감소 시킴
Out of Domain Data 성능 검증
in domain data에 없거나 부족한 data list up
서비스 배포를 위해 ODD dataset 으로 타사 대비 성능 검증
Personal insights
OCR 관련해서 공부를 해봤기도 해서 검출과 인식으로 모듈을 나눠서하는 것은 당연(?)하게 생각하고 있었다.
이 부분의 문제점부터 파고들어서 2개 모듈로 나누지않고 하나의 통합된 모듈로 모델 구조를 생각한것은 대단한 아이디어 같다. 이런 연구들을 보면 한 주제에 대한 깊은 고민도 필요하고, 당연하게 여겨지는 것들에 대해 도전하는게 필요하다는게 느껴진다.
실전에 강한지 검증하기 위해 OOV Challenge 에 참가해 문제정의하고 다양한 실험들을 시도하는 모습이 인상깊었다.
중요한 건 꺾이지 않는 마음: 스마트에디터의 도전
김성원, 이진/ NAVER ETECH SmartEditor
1. Intro
”끊임없이 시도하는 것이 우수해진다”
2. SE 도전기
- 과거부터 현재까지
- 1세대: contenteditable 문서를HTML 그대로저장
문제1 : 브라우저 대응의 어려움 문제2: 멀티 디바이스 대응의 어려움
- 1.5세대: 블록 에디터 일부(텍스트영역)contenteditable사용 문서모델링(JSON),블록별편집
문제발생: 어색한 Selection 동작
- 2세대: 가상 커서 + input buffer 1.5 세대에서 발생한 어색한 Selection 동작을 가상커서로 브라우저에 따라 다른 contenteditable 내부 동작 을 input buffer 로 해결
문제발생: 다국어 입력(IME) 처리 이슈 문제발생: 우 클릭 붙여넣기 이슈
- 현재
- 3세대: 가상 커서 + contenteditable 목표1: 기존 에디터의 사용성 유지 목표2: 브라우저 네이티브 활용 어려움 해소 React, MobX와 contenteditable을 함께 사용할 때 오류 발생
문제: contenteditable과 React를 함께 사용해 DOM과 vDOM 싱크 문제 발생 해결: DOM과 vDOM 싱크가 깨질 만한 상황은 나누어 관리하자.
-
긴 글 성능 문제 (undo, redo, 긴 글 불러오기, 긴 글 수정하기) Snapshot 방식의 경우, undo/redo 시 모든 컴포넌트 렌더링 발생 부분 snapshot 방식 데이터의 변경점만 기록
-
긴 코드 (스마트 에디터 경우 18만줄) 복잡도, 중복도 문제 중복도가 높아지는 이유 에디터 타입 별로 동작이 일부 다름 다양한 횡단 관심 존재 동기, 비동기 코드의 혼재 중단 처리 실패 처리 수정 명령을 하나의 블록으로 만들자! Action을 통한 문제해결
-
플랫폼으로서 다양한 디자인 요구 수용하기 IE 스펙 제외 CSSS 변수 Node SASS- Dart SASS 관심사 분리작업
-
Dart SASS를 이용한 운영 효율화
- 미래
- 동시 편집 yorkie
- AI
Personal insights
발표 내용이 자칫 지루할수있는데 도입부터 집중할수있게 구성되어있었다. 에디터를 만드는 일이 결코 쉬운일이 아니며 수많은 고민의 흔적과 문제를 해결한 것이 특허출원으로 하나씩 이어지는게 신기하면서도 감동적이었다. 에디터를 직접구현하지는 않고 오픈소스를 활용해 개발하였었는데 프론트 내용이지만 문제와 해결방식에선 배울점이 있었다.
SCDF로 하루 N만곡 이상 VIBE 메타 데이터 실시간으로 적재하기! : BATCH → SCDE 전환기
김대성/ NAVER TUNE
1. 대용량 데이터를 처리하는 2가지 방식
- 데이터를 다루는 프로그래밍 환경 대량의데이터를벌크(일괄)처리 무한한데이터를실시간(스트림)처리
- 더 많은 데이터를 더 빠르게 처리하는 기법 부하분산, 파티셔닝
- 누가 스트림 처리를 사용해야 할까? 데이터를수집하거나저장하지않는다. 무한한작은데이터가지속적으로유입되고이를연속으로처리한다. 데이터가도착하자마자…
ex. 신용카드 부정사용, 구매처리, 실시간 금 시세, 위치추적
2. 레거시 전환 계획과 전략
- 배치 + 젠킨스으로는 충분하지 않다.
2019.08.22 현재속도로는6년뒤에나1,270만곡적재가능
현재시스템의개발/운영하는방식에어떤 문제점이있는가? 새롭게개발하면서우리가얻고자하는가치는무엇인가? 어떠한기준을가장우선순위에두고아키텍처를설계할것인가? 어떤데이터저장소를사용하는게적합한것인가? 어떤 구현방식으로개발해서구축할것인가?
- STOP / SWITCH/ MODELING 기초공사 JenkinsJob->Stop Function->Switch MongoDB->Modeling
- Dual-Write로 데이터 적재하기
- RDBMS -> MongoDB 마이그레이션하기 https://github.com/johnlpage/MongoSyphon
- 배포, 롤백, 마이그레이션 전략 세우기
3. SCDF 스트림 구조와 설계
Microservice based Streaming and Batch data processing for Cloud Foundry and Kubernetes**
- Functional Interface로 개념 이해하기
- SCDF 컨셉 이해하기
- 데이터 플로우 이벤트 전달 방식의 이해 Event Driven Microservice Spring Cloud DataFlow
- 데이터 플로우 스트림 연결 방식의 이해
- 대표적인 엔트리포인트 소비 방식 3가지 카프카 토픽 이벤트를 소비(Consumer)한다. HTTP Request/Response 방식으로 소비한다. change data capture 방식으로소비한다.
- DAG 방향성 비순환 그래프 방식으로 설계하기 반복이나순환을허용하지않는다. 애플리케이션간의순환실행을방지하기위해서중요함.
- Fan-in & Fan-out 설계측정 모듈을계층적으로분석하거나시스템 복잡도를측정하는기법
- IO처리와 DB접근은 다르게 고민하기
4. SCDF 실 서비스 적용하기
- VIBE + SCDF 아키텍처 DataFlowServer 애플리케이션,스트림,등록/조회/삭제관리,스키퍼서버에배포위임
- SCDF 설치하기
- SCDF 개발하기 (Source, Processor, Sink)
- SCDF 모니터링하기
- SCDF 무중단 배포 전략
- SCDF 스케일링 기술을 이용한 성능 끌어올리기
Personal insights
대용량 데이터 실시간처리. 새로운 시스템 아키텍쳐를 설계할때 어떠한 부분들을 고려해야한다는걸 4년만에 성능을 100배 이상으로 끌어올리게 되는데, SCDF가 오픈소스임에도 상용 서비스 못지않게 다양한 기능들을 제공하고 있어서 대쉬보드, autoscaling 까지. 대용량 데이터 처리도 아직 해보진 못했어서 카프카 부터 조금 공부해봐야겠다는 생각을 하게되었음
루다, 눈을 뜨다! AI 챗봇 서비스에 이미지 대화 기술 적용시키기
이재훈 / 스캐터랩
5만 장의 사진, 15만 개의 문장으로 루다가 사진을 보고 말을 할 수 있게 합니다.
1. 이미지 코멘팅 태스크
- 이미지 코멘팅 태스크 정의 대화를 통해 유저와 관계를 형성하고 더 좋은 대화를 통해 유저와 더 깊은 관계를 맺는 것 이미지 대화가 불가능, 유저가 보낸 이미지에 대해 정해진 답변이 나감 관련된 연구들로는 Image Captioning , Visual Question Answering 태스크가 있음
- 이미지 코멘트 데이터셋 AI Hub 데이터셋과 Open Images Dataset 을 활용 사람, 음식, 장소, 동물, 기타
- 이미지 코멘트 레이블링 일반적인/ 구체적인 표현의 코멘트를 받기위해 코멘트 유형을 만들고 다르 의미가 담기도록 레이블링 유도 다양한 시각으로 바라보는 코멘트를 받기 위해 한 이미지에 대해 두 명 이상의 레이블링 실제 대화처럼 자연스러운 코멘트를 받기 위해 최소한의 가이드라인, 최대한의 예시를 제작
2. 이미지 코멘팅 모델
- 이미지 코멘팅 모델 설계 이미지와 언어에 대한 복합적인 지식을 배우는 Vision-Language Pre-training (VLP) 방법과 모델이 연구되어오고 있음
- 이미지 코멘팅 모델 개발 리트리벌 모델 대표적으로 사용되는 Dual Encoder 구조인 CLIP을 사용
생성 모델 Vision Encoderr 와 Text Decoderr 를 연결한 Encoder-Decoder 구조를 사용
- 이미지 코멘팅 모델 평가 정량평가 정성평가 - Sensibleness-Specificity Average 답변이 이미지의 내용과 모순되지 않고 자연스러운지, 답변이 이미지의 세부 사항과 관련된 내용인지
3. 포토챗 베타
- 포토챗 기술 적용 후 대화 루다 2.0 출시 생성 방식의 텍스트 대화 모델에 리트리벌 방식의 이미지 대화 모델을 결합
- 현재 포토챗 베타의 한계 리트리벌 모델의 한계 이미지 인식 성능의 한계로 디테일한 구분이 어려움, 답변 후보 문장들은 유한하므로 표현력이 부족함 이미지에 대한 답변 이외의 대화에는 이미지에 대한 정보가 들어가지 않은 언어 모델을 이용
- 향후 연구 방향 생성 기반 이미지 코멘팅 모델 멀티모달 컨텍스트 대화 모델 scene-Text를 활용한 대화 모델
4. 생성 기반 포토챗
- 생성 기반 이미지 대화 모델 설계 이미지에 대한 답변을 이전 대화 문맥까지 고려하여 생성하는 모델을 만들자
- 생성 기반 이미지 대화 모델 개발
- 결과 맛보기
Personal insights
루다를 사용해보면서 대화가 매끄럽게 잘 이어진다고 생각했었는데, 실제로 카톡을 주고받는것과 같이 포토챗 기능이 구현되어있고 생성모델을 적용해 조금더 매끄럽고 자연스러운 대화를 시도